介绍
本篇文章给大家分享的是有关kubernetes中怎么利用map/reduce模式实现优选计算,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
<节> <节> <节>
1。设计基础
<节> <节> <节> <节>,,,1.1两阶段:单点与聚合
<节>在进行优选的时候,除了最后一次计算,在进行针对单个算法的计算的时候,会分为两个阶段:单点和聚合
<节>在单点阶段,会根据当前算法针对单个节点计算在聚合阶段,则会根据当前单点阶段计算完成后,来进行聚合
<节> <节> <节> <节>,,,1.2并行:节点与算法
<节>单点和聚合两阶段在计算的时候,都是并行的,但是对象则不同,其中单点阶段并行是针对单个节点的计算,而聚合阶段则是针对算法级别的计算,通过这种设计分离计算,从而避免多goroutine之间数据竞争,无锁加速优选的计算
<节> <节> <节> <节>,,,1.3地图与减少
<节>而地图与减少则是针对一个上面并行的两种具体实现,其中地图中负责打单节点分,而减少则是针对地图阶段的打分进行聚合后,根据汇总的结果进行二次打分计算
<节> <节> <节> <节>,,,1.4重量
<节>map/reduce阶段都是通过算法计算,如果我们要进行自定义的调整,针对单个算法,我们可以调整其在预选流程中的权重,从而进行定制自己的预选流程,
<节> <节> <节> <节>,,,1.5随机分布
<节>当进行优先级判断的时候,肯定会出现多个节点优先级相同的情况,在优选节点的时候,会进行随机计算,从而决定是否用当前优先级相同的节点替换之前的最合适的节点
<节> <节>2。源码分析,
<节>优选的核心流程主要是在PrioritizeNodes中,这里只介绍其关键的核心数据结构设计
<节> <节> <节> <节>,,,2.1无锁计算结果保存
<节>无锁计算结果的保存主要是通过下面的二维数组实现,如果要存储一个算法针对某个节点的结果,其实只需要通过两个索引即可:算法索引和节点索引,同理如果我把针对单个节点的索引分配给一个goroutine,则其去其他的goroutine则就可以并行计算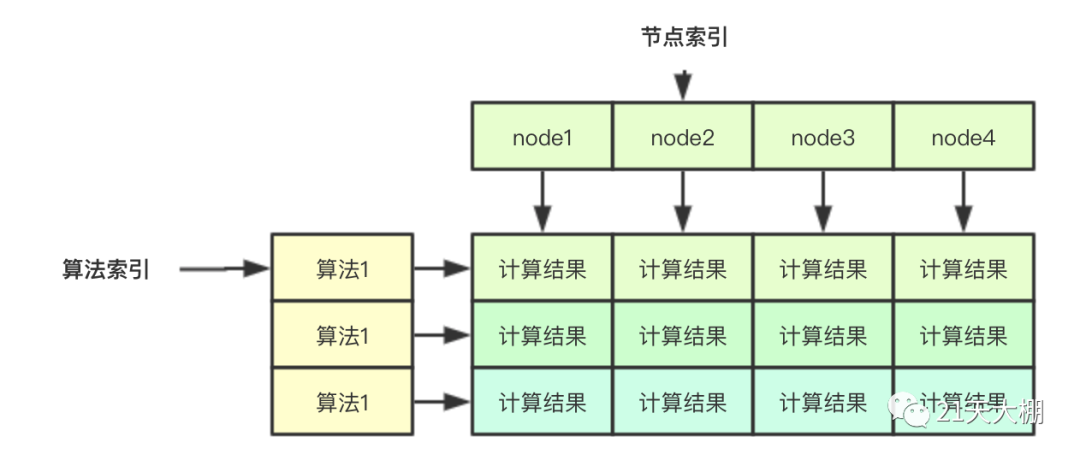
<代码>//在计算的时候,会传入节点[]* v1。节点的数组,存储所有的节点,节点索引主要是指的该部分, <节> <节> <节> <节>,,,
结果:=([]schedulerapi。HostPriorityList, len (priorityConfigs), len (priorityConfigs))
![kubernetes中怎么利用Map/reduce模式实现优选计算“>之前在预选阶段介绍过ParallelizeUntil函数的实现,其根据传入的数量来生成计算索引,放陈入中,后续多个goroutine从陈中取出数据直接进行计算即可</p> </节> <节> <pre> <代码> workqueue.ParallelizeUntil (context.TODO(), 16日,len(节点),函数(指数int) {<br/>,,,,//根据节点和配置的算法进行计算<br/>,,,,nodeInfo:=nodeNameToInfo[节点(指数)。名称]<br/>,,,,,,//获取算法的索引<br/>,,,,因为我:=范围priorityConfigs {<br/>,,,,,,如果priorityConfigs[我]。函数!=nil {<br/>,,,,,,,,继续<br/>,,,,,}<br/> <br/>,,,,,,var犯错误差<br/>,,,,,,,,<br/>,,,,,,,//通过节点索引,来进行针对单个节点的计算结果的保存<br/>,,,,,[我](指数),结果,呃=priorityConfigs[我]。地图(pod、元nodeInfo) <br/>,,,,,,如果犯错!=nil {<br/>,,,,,,,,appendError (err) <br/>,,,,,,,结果[我](指数)。主机=节点(指数)。名称<br/>,,,,,}<br/>大敌;,,}<br/>大敌;,})<br/> </代码> </pre>
,</节> <节> <节> <节> <节>,,,<h3> 2.3基于算法索引的减少计算</h3> </节> </节> </节> </节> <节> <p> <img src=](/zixun/d/file/fuwuqi/2021-08-10/d0822320646ac234fb29929133824deb.png )