介绍
本篇文章为大家展示了中文预训练模型厄尼该如何使用,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
最近在工作上处理的都是中文语料,也尝试了一些最近放出来的预训练模型(厄尼,BERT-CHINESE WWM-BERT-CHINESE),比对之后还是觉得百度的厄尼效果会比较好,而且使用十分方便,所以今天就详细地记录一下。希望大家也都能在自己的项目上取得进展~
<强> 1 <强>, <强>一眼厄尼
<强> 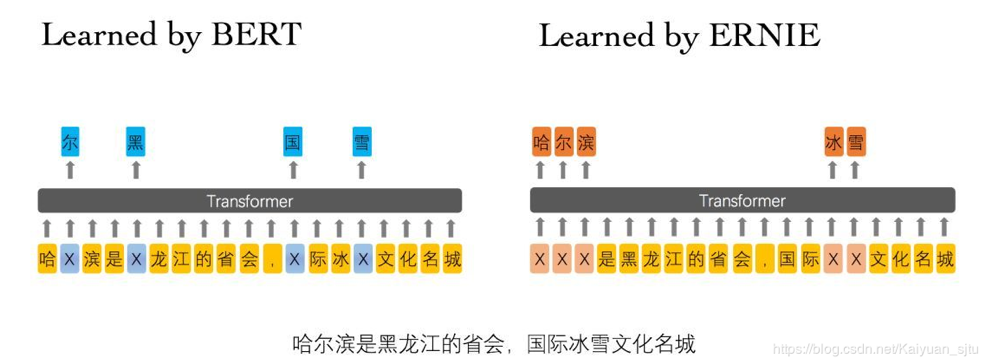 <李>
<李>
token_ids:输入句子对的表示,
<李>sentence_type_ids: 0或者1表示牌属于哪一个句子。
<李>position_ids:绝对位置编码
<李>seg_labels:表示分词边界信息,0表示词首,1表示非词首,1为占位符
<李>next_sentence_label:表示该句子对是否存在上下句的关系(0为无1为有)
<强> reader.pretraining.py <强>中的 <强> parse_line <强>函数强。