今天小编给大家分享一下linux上numa架构实例分析的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。

以下案例基于 Ubuntu 16.04,同样适用于其他的 Linux 系统。我使用的案例环境如下所示:
机器配置:32 CPU,64GB 内存
在NUMA中储存层次的概念:
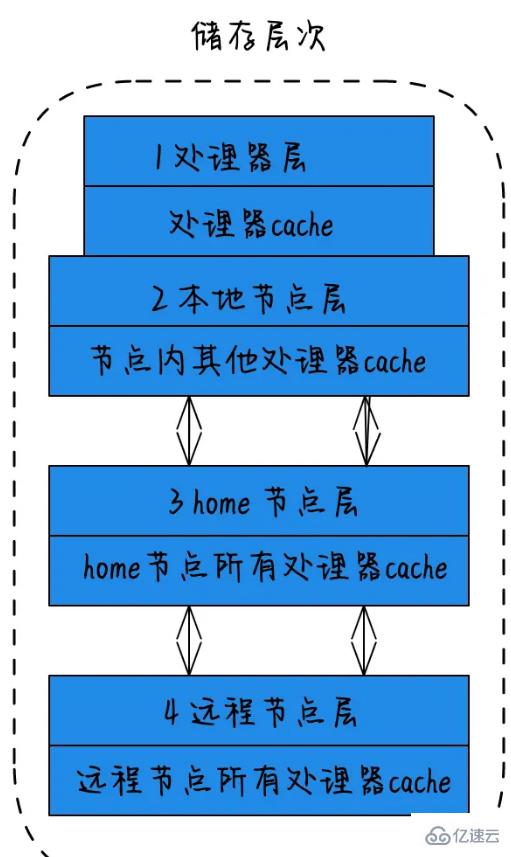
1)处理器层:单个物理核,称为处理器层。
2)本地节点层:对于某个节点中的所有处理器,此节点称为本地节点。
3)home节点层:与本地节点相邻的节点称为home节点。
4)远程节点层:非本地节点或邻居节点的节点,称为远程节点。CPU访问不同类型节点内存的速度是不相同的,访问本地节点的速度最快,访问远端节点的速度最慢,即访问速度与节点的距离有关,距离越远访问速度越慢,此距离称作Node Distance。应用程序要尽量的减少不同CPU模块之间的交互,如果应用程序能有方法固定在一个CPU模块里,那么应用的性能将会有很大的提升。
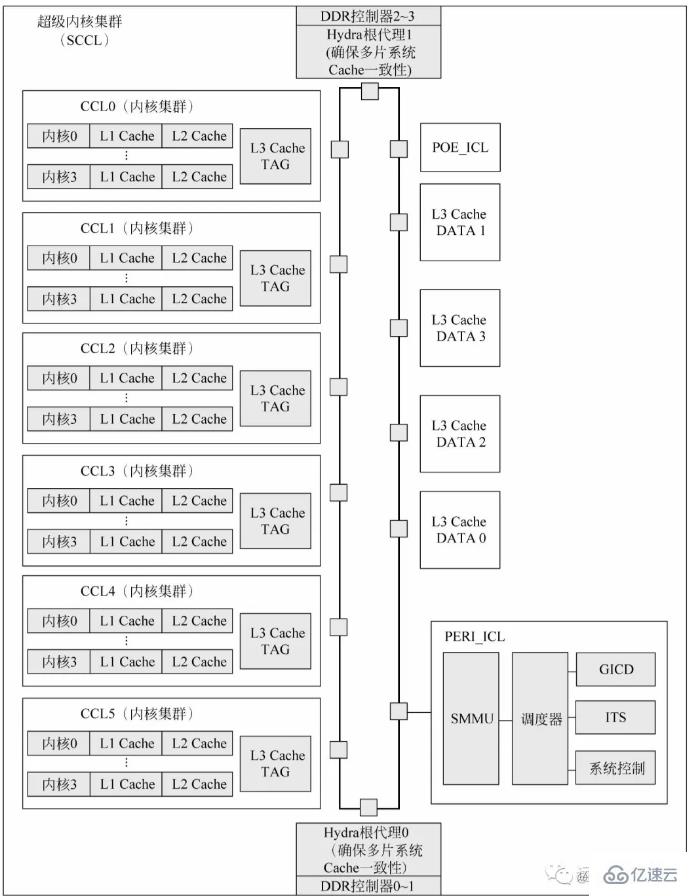
**以鲲鹏920处理器讲一下cpu芯片的的构成:**鲲鹏920处理器片上系统的每个超级内核集群包含6个内核集群、2个I/O集群和4个DDR控制器。每个超级内核集群封装成一个CPU晶片。每个晶片上集成了4个72位(64位数据加8位ECC)、数据传输率最高为3200MT/s的高速DDR4通道,单晶片可支持最多512GB×4的DDR存储空间。L3 Cache在物理上被分为两部分:L3 Cache TAG和L3 Cache DATA。L3 Cache TAG集成在每个内核集群中,以降低监听延迟。L3 Cache DATA则直接连接片上总线。Hydra根代理(Hydra Home Agent,HHA)是处理多芯片系统Cache一致性协议的模块。POE_ICL是系统配置的硬件加速器,一般可以用作分组顺序整理器、消息队列、消息分发或者实现某个处理器内核的特定任务等。此外,每个超级内核集群在物理上还配置了一个通用中断控制器分发器(GICD)模块,兼容ARM的GICv4规范。当单芯片或多芯片系统中有多个超级内核集群时,只有一个GICD对系统软件可见。
numactl的使用
Linux提供了一个一个手工调优的命令numactl(默认不安装),在Ubuntu上的安装命令如下:
sudo apt install numactl -y
首先你可以通过man numactl或者numactl --h了解参数的作用与输出的内容。查看系统的numa状态:
numactl --hardware
运行得到如下的结果:
available: 4 nodes (0-3) node 0, cpu: 0, 1, 2, 3, 4, 5, 6, 7 node 0,大小:16047,MB node 0,免费的:3937,MB node 1, cpu:, 8, 9, 10, 11, 12日,13日,14日,15日 node 1,尺寸:16126,MB node 1,免费的:4554,MB node 2, cpu: 16, 17, 18, 19, 20日,21日,22日,23日 node 2,大小:16126,MB node 2,免费的:8403,MB node 3, cpu:, 24日,25日,26日,27日,28日,29日,30日,31日 node 3,大小:16126,MB node 3,免费的:7774,MB node 距离: 0 node ,,,,, 1,,, 2,, 3 ,,0:,10,,20,,20,20 1:,才能,20,,10,,20,20 2:,才能,20,,20,,10,20 3:,才能,20,,20,,20,,10
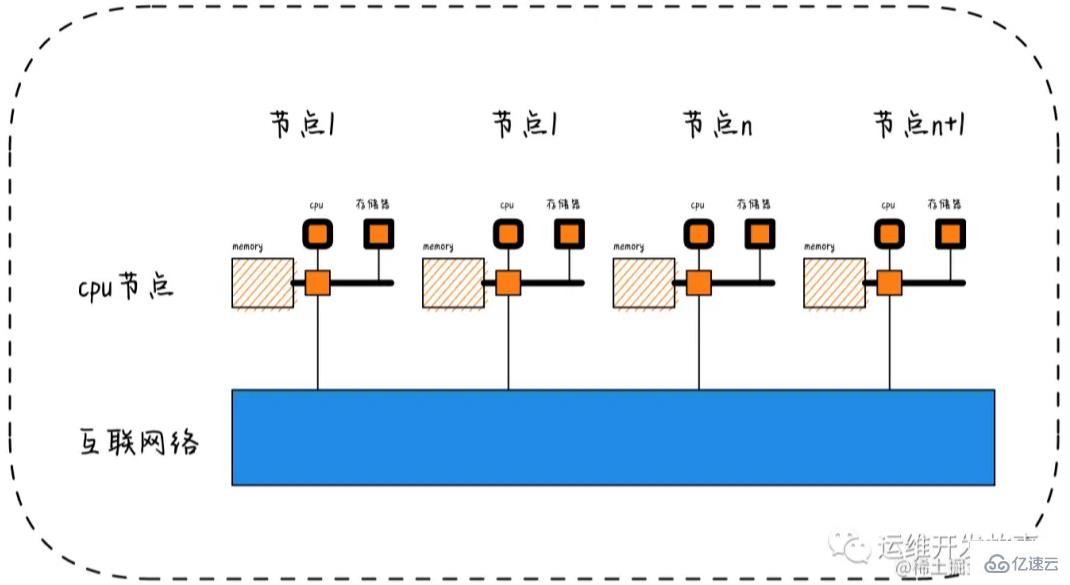
根据这个图与命令得到的结果,可以看的到,此系统共有4个节点,各领取8个CPU和16 g内存。这里还需要注意的就是CPU共享的L3缓存也是会自己领取相应的空间。通过numastat命令可以查看numa状态,返回值内容:
numa_hit:是打算在该节点上分配内存,最后从这个节点分配的次数;
numa_miss:是打算在该节点分配内存,最后却从其他节点分配的次数;
numa_foreign:是打算在其他节点分配内存,最后却从这个节点分配的次数;
interleave_hit:采用交错策略最后从本节点分配的次数
local_node:该节点上的进程在该节点上分配的次数
other_node:是其他节点进程在该节点上分配的次数
注:如果发现numa_miss数值比较高时,说明需要对分配策略进行调整,例如将指定进程关联绑定到指定的CPU上,从而提高内存命中率。