一、饲养员介绍
<>之前,它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护,名字服务,分布式同步,组服务等1。命名服务2。配置管理3。集群管理4。分布式锁5。队列管理
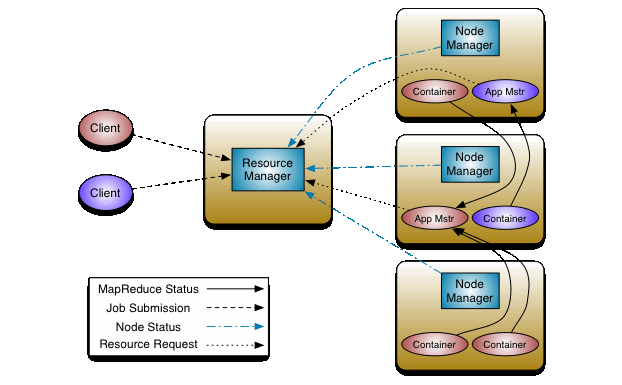
二,饲养员架构的架构模型
客户机-服务器模型:用于对分布式协调系统中的对象提供协调服务,
对等模型:用于在动物园管理员集群内交互数据;
这种混合的体系结构,让管理员既保持客户端的简单化,又能够在集群内部保持一个良好的高可用机制;管理员的两种运行模式:独立和法定人数
独立模式: 代表管理员由一个单一节点构成,它的数据并不需要再多个节点之间复制;
quorum模式: 该模式主要多用于生产环境,动物园管理员有多个节点后构成一个集群,通过管理员的领导选举,集群节点间的数据同步有关;
当才用群体模式时,它的基本运转流程是:
①选举领袖<代码>
②同步数据
③选举<代码> 领袖过程中算法有很多,但要达到的选举标准是一致的;
④领袖要具有最高的zxid
⑤集群中大多数的机器得到相应并<代码>遵循选出的领袖<代码>
说明:
<>之前对于用户的读操作,饲养员集群中的所有节点都可接收处理; 对于用户的写操作,zookeeper将它作为事务进行处理,并只有Leader才能发起事务;在每次提交之前,修改的数据要在集群中同步;三、数据模型
zookeeper是通过集中性的C/S架构服务于客户端的,采用的是点对点的Pair-Pair架构在各节点间进行同步数据,zookeeper内部的数据结构和数据类型采用了精简的方式提供给用户使用
在数据结构上,zookeeper采用的是树形结构;树种的节点被称为
znode,在整棵树种有着清晰的父子层次关系;zookeeper对数据的修改都当做一次事务来看待,每次的事务动作都是原子操作,并分配一个唯一的zxid(zookeeper transacation id);
在每一个znode中都记录了与之相关的
zxid;znode除了有效载荷数据,还包括如下属性:czxid:引发当前znode改变的zxid
mzxid:当前znode上一次修改前的zxid
ctime:对znode事务操作所花费的时间,单位是毫秒
mtime:操作上一次znode事务所花费的时间,单位是毫秒
version:关联到zxid,znode自身版本属性,当前znode修改的次数
cversion:znode子节点的修改次数
aversion:znode ACL(访问列表)的修改测试
ephemeralOwner:记录客户端会话ID,如果是持久型znode 则为0
dataLength:znode数据字段的长度
numChildren:znode子节点的个数
1、持久型与短暂型的znode【对应于ephemeralOwner属性】
znode在创建的时候可以指定模式,可以用不同的模式组合成需要的分布式场景功能;
一个znode节点可以是持久的(Persistent),也可以是短暂的(Ephemera);
区别:
持久型: 只有收到删除命令后才能被删除;
用于保存结构信息;
短暂型: 会在客户端与服务端之间保存的会话中断时自动删除;
也能像持久型znode一样被命令删除;
客户端与服务端之间一旦建立连接,则会有定期的心跳检查以保证这个长连接的存活
2、序列znode
创建znode时会自动分配一个唯一的递增的整数,这个正向序列可以作为路径名称的一部分;
例如:客户端创建了一个序列znode为
/woker/work-,则zookeeper会自动分配一个序列数,如果是当前znode下的第一个子节点则分配为1,路径变为/worker/work-1;序列节点最大的作用就是生成唯一名称节点,同时能够提供节点间的创建次序信息3、ACL【访问列表】
zookeeper的ACL建立在认证与授权机制下,包含以下认证方式:
1. digest:通过用户名/密码对客户端进行认证; 2只sasl:支持客户端通过Kerberos认证; 3只;ip:通过ip地址对客户端进行认证;在授权方面,ACL可以对znode的创建(子节点),读取,写入,删除及管理(设置ACL)进行控制
未完待续…
【分布式协调管理员】基础篇