事故背景:
<代码>物理机(192.168.200.10)安装了KVM虚拟化,虚拟化的机器无法正常启动,进入vnc界面查看到linux系统在读取硬盘的时候需要30 s-60s左右,正常启动的话几秒钟即可。怀疑是和硬盘有关系。
解决思路:
1,查看当前系统硬盘负载情况
2,查看哪个进程占用了硬盘IO
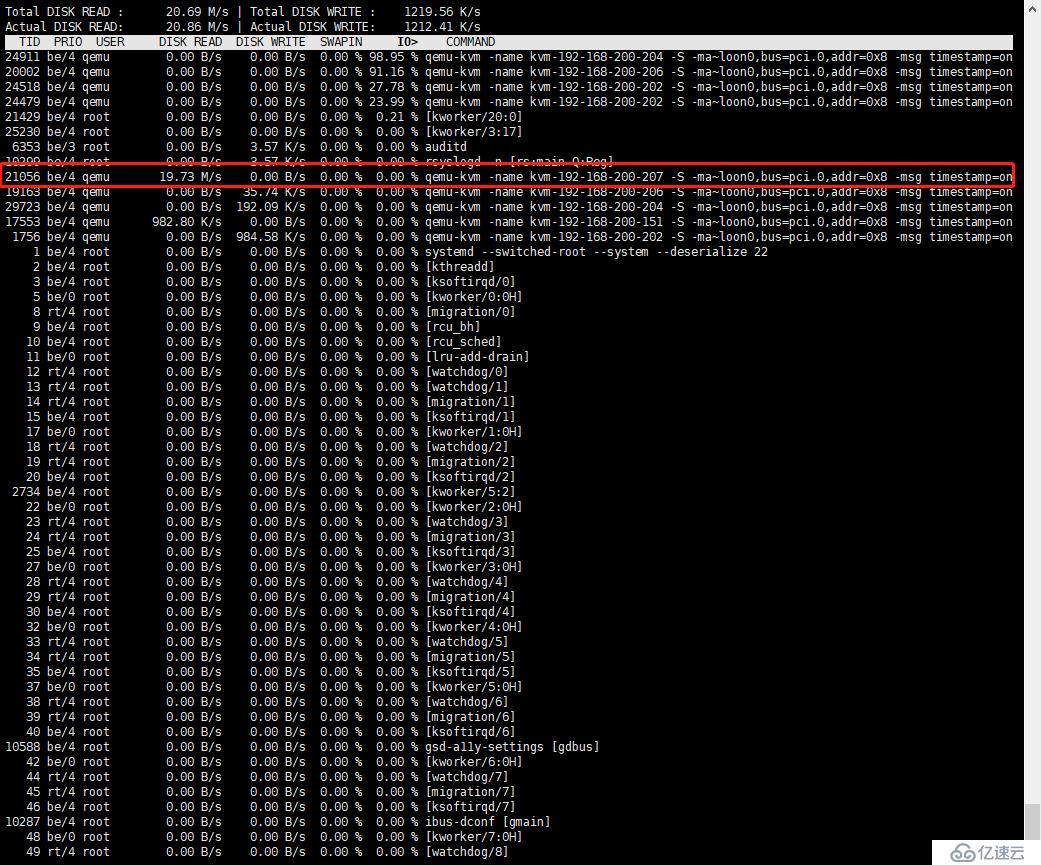
步骤1,使用iostat - x 1 iostat还有一个比较常用的选项- x,该选项将用于显示和io相关的扩展数据。如图
<代码> rrqm/s:每秒这个设备相关的读取请求有多少被合并了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同块的数据,FS会将这个请求合并合并);wrqm/s:每秒这个设备相关的写入请求有多少被合并了。 rsec/s:每秒读取的扇区数; wsec/:每秒写入的扇区数。 岩石层/s:读请求的数量都发给设备每秒; wKB/s:写请求的数量,发行到设备/秒; avgrq-sz平均请求扇区的大小 avgqu-sz是平均请求队列的长度。毫无疑问,队列长度越短越好。 等待:每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5 ms,如果大于10 ms就比较大了。 这个时间包括了队列时间和服务时间,也就是说,一般情况下,等待大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。 svctm表示平均每次设备的I/O操作的服务时间(以毫秒为单位)。如果svctm的值与等待很接近,表示几乎没有I/O等待,磁盘性能很好,如果等待的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢。 % util:在统计时间内所有处理IO时间,除以总共统计时间,例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的% util=0.8/1=80%,所以该参数暗示了设备的繁忙程度 ,一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%实效是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
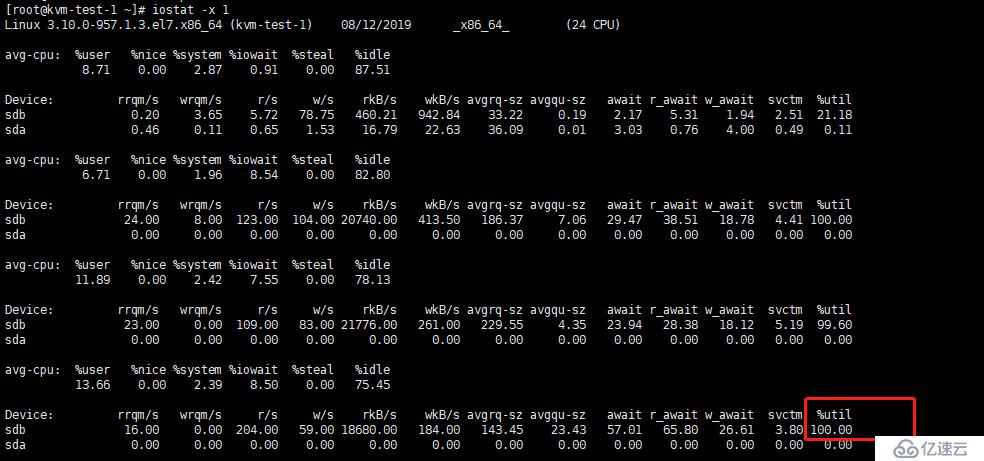
由此得出:硬盘的负载已达到瓶颈;