R语言中的Anosim分析该如何理解,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
<节> <节> <节> <节>无论是野外环境样品,还是室内试验样品,一般我们都会设置样方或平行样来增强分析的准确性,必要时还会进行区组设计,因此在数据分析中需要进行组间差异的比较判别。然而对于微生物群落数据,由于物种繁多,而且不同物种的敏感环境因子不同,因此基于正态分布的参数检验难以满足分析需要,要进行多元非参数检验(非参数多变量统计测试)来计算显著性,R语言素食包含有多种非参数检验方法,包括Anosim,阿多尼斯,MRPP等,不同方法在统计量的选择,零模型等方面存在差异。
<节> Anosim ,分析( 分析相似之处 ,)是一种基于置换检验和秩和检验的非参数检验方法,用来检验组间的差异是否显著大于组内差异,从而判断分组是否有意义。 ,Anosim ,分析使用距离进行分析,默认为 ,方法=癰ray" ,,可以选择其他距离(和 ,vegdist () ,函数相同),也可以直接使用距离矩阵进行分析,在 ,R ,中我们可以使用 ,素食 ,包中的 ,anosim () ,函数进行分析,这里我们微生物 ,群落数据为例进行分析: <节>#读取抽平后的OTU_table和环境因子信息data=https://www.yisu.com/zixun/read.csv (“otu_table.csv”,标题=TRUE, row.names=1) envir=read.table (“environment.txt”,头=TRUE) rownames (envir)=envir [1] env=envir[1] #筛选高丰度物种并将物种数据标准化意味着=应用数据(数据,1,意味着)otu=[名称(意味着[意味着> 10])]otu=t (otu) #根据地理距离聚类公里=kmeans (env,中心=3,nstart=22)位置=因素(公里集群美元)#进行Anosim分析图书馆(素食)Anosim=Anosim (otu、位置、排列=999)总结(Anosim)

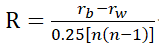
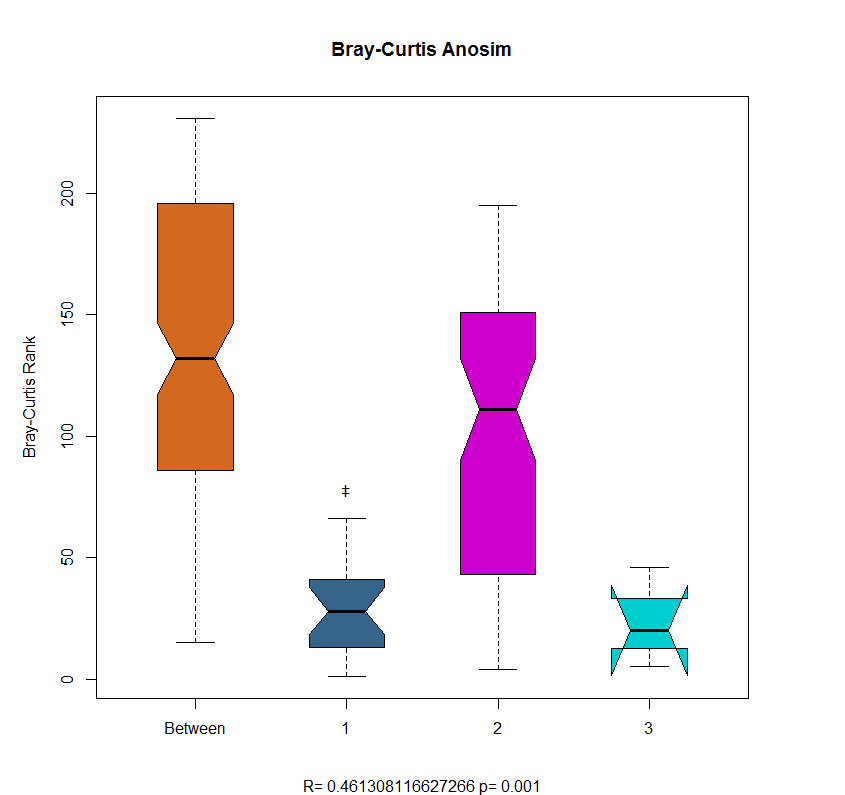
假如R> 0,说明组内距离小于组间距离,也即分组是有效的,这与方差分析中比较组内方差与组间方差来判断的原理是类似的。由上面分析结果可以看到R=0.4613,大于零模型99%分位数0.290,因此p值为0.001,结果是显著的。我们可以提取分析结果,如下为距离的秩:

因为有22个样品,所以应该有C(22日2)=231个距离。如下为上述距离对应的归属:

mycol=C (52619453、71134448548655574、36544、89120131596147576) mycol=颜色()[mycol] par (mar=C(5 5 5 5))=结果粘贴(“R=? Anosim美元统计,“p=?, Anosim signif美元)箱线图(Anosim dis.rank ~ Anosim class.vec,美元,pch=?“,,=mycol,上校,范围=1,boxwex=0.5,=TRUE,, ylab=癇ray-Curtis Rank",,主要=癇ray-Curtis Anosim",,子=结果)<>节作图结果如下所示:
看完上述内容,你们掌握R语言中的Anosim分析该如何理解的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注行业资讯频道,感谢各位的阅读!