
这篇文章将为大家详细讲解有关怎么为时间序列数据优化K-均值聚类速度,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
时间序列数据(Time Series Data)是按时间排序的数据,利率、汇率和股价等都是时间序列数据。时间序列数据的时间间隔可以是分和秒(如高频金融数据),也可以是日、周、月、季度、年以及甚至更大的时间单位。数据分析解决方案提供商 New Relic 在其博客上介绍了为时间序列数据优化 K-均值聚类速度的方法。笔者对本文进行了编译介绍。
在 New Relic,我们每分钟都会收集到 13.7 亿个数据点。我们为我们的客户收集、分析和展示的很大一部分数据都是时间序列数据。为了创建应用与其它实体(比如服务器和容器)之间的关系,以便打造 New Relic Radar 这样的新型智能产品,我们正在不断探索更快更有效的对时间序列数据分组的方法。鉴于我们所收集的数据的量是如此巨大,更快的聚类时间至关重要。
加速 k-均值聚类
k-均值聚类是一种流行的分组数据的方法。k-均值方法的基本原理涉及到确定每个数据点之间的距离并将它们分组成有意义的聚类。我们通常使用平面上的二维数据来演示这个过程。以超过二维的方式聚类当然是可行的,但可视化这种数据的过程会变得更为复杂。比如,下图给出了 k-均值聚类在两个任意维度上经过几次迭代的收敛情况:
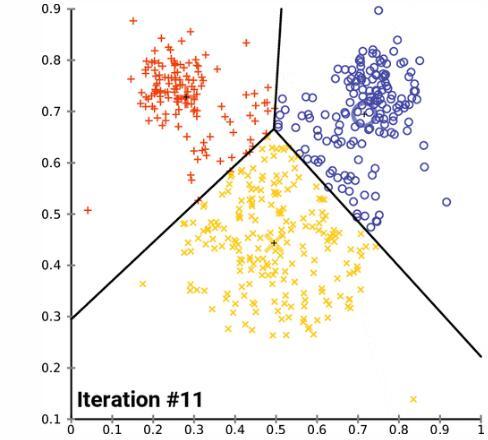
不幸的是,这种方法并不能很好地用于时间序列数据,因为它们通常是随时间变化的一维数据。但是,我们仍然可以使用一些不同的函数来计算两个时间序列数据之间的距离因子(distance factor)。在这些案例中,我们可以使用均方误差(MSE)来探索不同的 k-均值实现。在测试这些实现的过程中,我们注意到很多实现的表现水平都有严重的问题,但我们仍然可以演示加速 k-均值聚类的可能方法,在某些案例中甚至能实现一个数量级的速度提升。
这里我们将使用 Python 的 NumPy 软件包。如果你决定上手跟着练习,你可以直接将这些代码复制和粘贴到 Jupyter Notebook 中。让我们从导入软件包开始吧,这是我们一直要用到的东西:
import time import numpy as np import matplotlib.pyplot as plt %matplotlib inline
在接下来的测试中,我们首先生成 10000 个随机时间序列数据,每个数据的样本长度为 500。然后我们向随机长度的正弦波添加噪声。尽管这一类数据对 k-均值聚类方法而言并不理想,但它足以完成未优化的实现。
n = 10000 ts_len = 500 phases = np.array(np.random.randint(0, 50, [n, 2])) pure = np.sin([np.linspace(-np.pi * x[0], -np.pi * x[1], ts_len) for x in phases]) noise = np.array([np.random.normal(0, 1, ts_len) for x in range(n)]) signals = pure * noise # Normalize everything between 0 and 1 signals += np.abs(np.min(signals)) signals /= np.max(signals) plt.plot(signals[0])
***个实现
让我们从最基本和最直接的实现开始吧。euclid_dist 可以为距离函数实现一个简单的 MSE 估计器,k_means 可以实现基本的 k-均值算法。我们从我们的初始数据集中选择了 num_clust 随机时间序列数据作为质心(代表每个聚类的中心)。在 num_iter 次迭代的过程中,我们会持续不断地移动质心,同时最小化这些质心与其它时间序列数据之间的距离。
def euclid_dist(t1, t2): return np.sqrt(((t1-t2)**2).sum()) def k_means(data, num_clust, num_iter): centroids = signals[np.random.randint(0, signals.shape[0], num_clust)] for n in range(num_iter): assignments={} for ind, i in enumerate(data): min_dist = float('inf') closest_clust = None for c_ind, j in enumerate(centroids): dist = euclid_dist(i, j) if dist 怎么为时间序列数据优化K -均值聚类速度




