介绍
小编给大家分享一下大数据中链表如何进行排序,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获、下面让我们一起去了解一下吧!
<强>算法:
对于链表的排序,一般要设计到拆分合并两步,拆分这一步:
中间节点作为临界值,小的放左边,大的放右边
合并操作步骤:
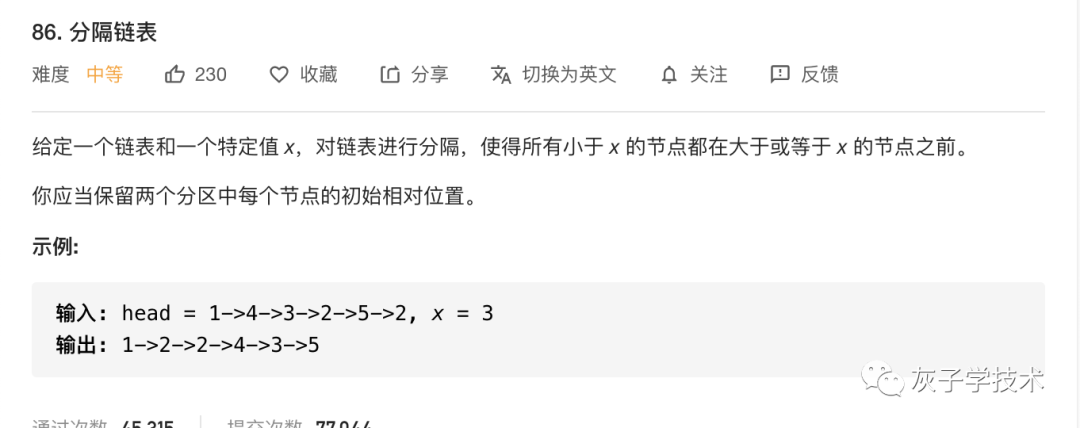
题目1:分隔链表
https://leetcode-cn.com/problems/partition-list/submissions/
代码实现:
/** * Definition for singly-linked list. * type ListNode struct { * Val int * Next *ListNode * } */func partition(head *ListNode, x int) *ListNode { if head == nil { return nil } curr := head before := new(ListNode) before1 := before after := new(ListNode) after1 := after for curr != nil { if curr.Val < x { before.Next = curr before = before.Next } else { after.Next = curr after= after.Next } curr = curr.Next } before.Next = nil after.Next = nil if after1.Next != nil { before.Next = after1.Next // after1记录偏移之前的after首节点位置 } return before1.Next // 原因是before1首节点是一个none的节点。}/* 解法:这个可以拆分成,两个链表,小于x的放到before,大于等于的放到after.然后将这两个链表拼接起来。*/
执行结果:

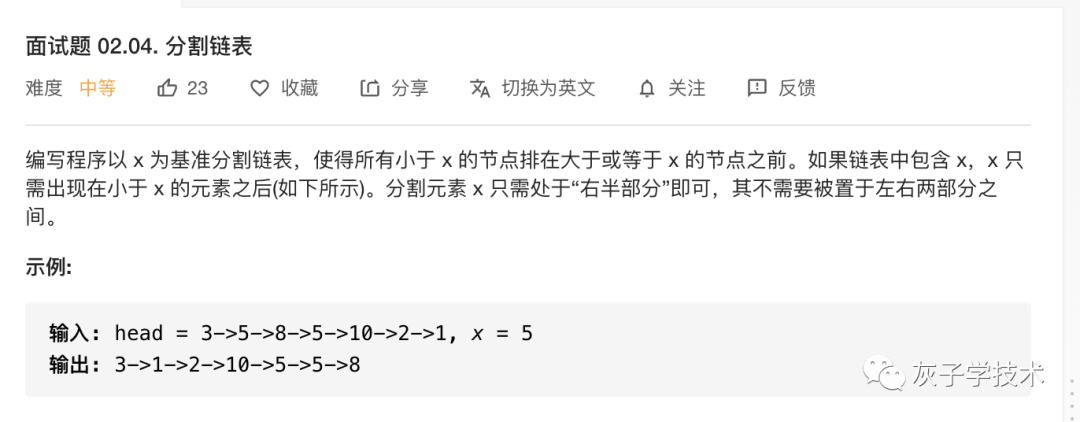
题目2:
https://leetcode-cn.com/problems/partition-list-lcci/submissions/
代码实现:
/** * Definition for singly-linked list. * type ListNode struct { * Val int * Next *ListNode * } */func partition(head *ListNode, x int) *ListNode { l1, l2 := new(ListNode),new(ListNode) res,res1 := l1,l2 for head != nil { if head.Val < x { l1.Next = &ListNode{Val:head.Val} l1 = l1.Next } else { l2.Next = &ListNode{Val:head.Val} l2 = l2.Next } head = head.Next } l1.Next = res1.Next return res.Next}// 双指针排序,小于x的放到l1,大于x的放在l2; 最后将两个链表串起来
null
null