Flink作为流批统一的计算框架,在1.10中完成了大量批相关的增强与改进.1.10可以说是第一个成熟的生产可用的Flink批SQL版本,它一扫之前的数据集的羸弱,从功能和性能上都有大幅改进,以下我从架构,外部系统集成,实践三个方面进行阐述。
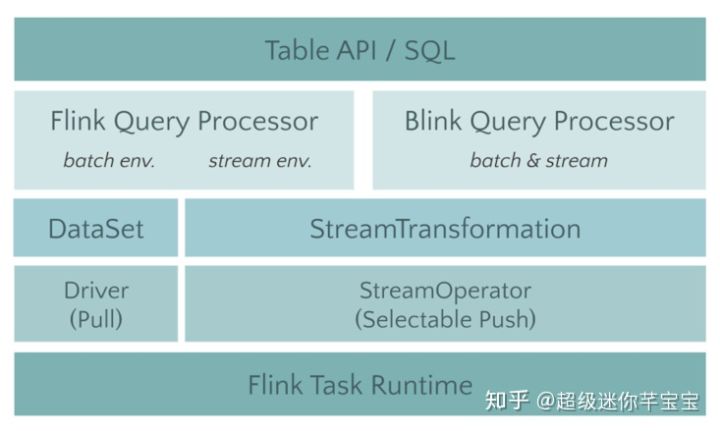
架构
堆栈
目前一个TaskManager里面含有多个插槽,在批作业中,一个槽里只能运行一个任务(关闭SlotShare)。
对内存来说,单个TM会把管理内存切分成槽粒度,如果1个TM中有n个槽,也就是任务能拿到1/n的管理内存。
我们在1.10做了重大的一个改进就是:任务链中起来的各个运营商按照比例来瓜分内存,所以现在配置的算子内存都是一个比例值,实际拿到的还要根据槽的内存来瓜分。
这样做的一个重要好处是:
-
<李>不管当前槽有多少内存,作业能都运行起来,这大大提高了开箱即用。
<李>不管当前槽有多少内存,运营商都会把内存瓜分干净,不会存在浪费的可能。
当然,为了运行的效率,我们一般建议单个插槽的管理内存应该大于500 mb。
另一个事情,在1.10后,我们去除了OnHeap的管理内存,所以只有堆外的管理内存。
外部系统集成
蜂巢强烈推荐蜂巢目录+蜂巢,这也是目前批处理最成熟的架构。在1.10中,除了对以前功能的完善以外,其它做了几件事:
-
<李>多版本支持,支持蜂巢1。X 2。李X 3. X
<李>完善了分区的支持,包括分区读,动态/静态分区写,分区统计信息的支持。
<李>集成蜂巢内置函数,可以通过以下方式来加载:
) TableEnvironment.loadModule (“hiveModule",新的HiveModule (“hiveVersion")) <李>优化了兽人的性能读,使用向量化的读取方式,但是目前只支持蜂巢2 +版本,且要求列没有复杂类型。有没有进行过优化差距在5倍量级。