1,日志的采集
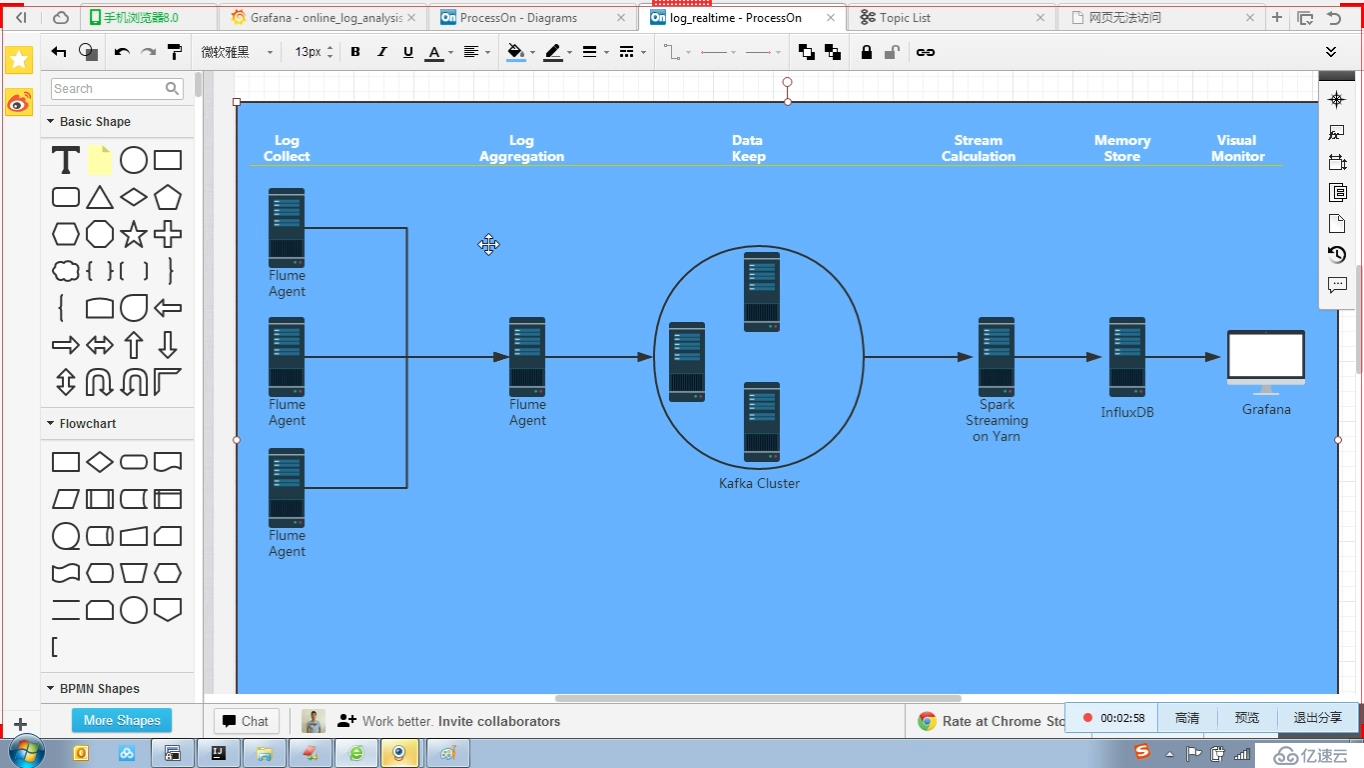
从水槽代理上的数据一般分到两条线上一条是卡夫卡集群,后期可以用流式处理(火花流或风暴等等)一条是到hdfs,后期可以用蜂巢处理,
业界叫λ架构建筑(一般公司的推荐系统,就是用这种架构)
flume-ng代理采集收集日志后,聚合在一个节点上(也可以不聚合)
为什么要聚合?为什么不直接写到卡夫卡集群?
假如公司规模比较大,有无数个水槽节点,这么多都连卡夫卡,会增加复杂度,有个聚合节点(会是多个节点组成,防止单节点挂了),还可以对日志格式统一处理,筛选不要的数据
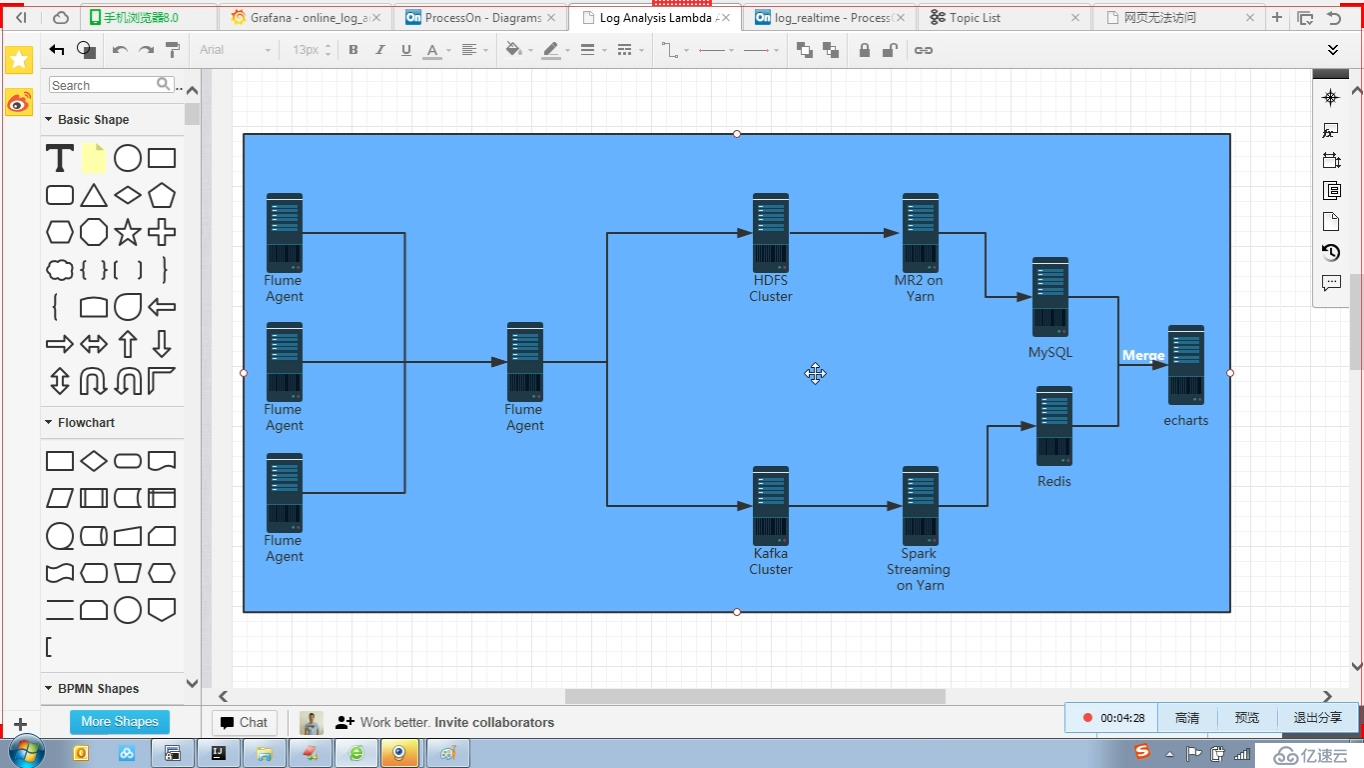
hdfs可以永久保存数据,可先生以处理多久数据都行
卡夫卡集群数据可以存储一定时间不能长期存储,sparkstreaming只能处理一定时间访问内数据风暴流
数据源nginx日志,mysql日志,tomcat日志等等→
水槽→
卡夫卡消息件消息发送到这里缓存数据一段时间,→
火花流+ sql火花alt="在线日志分析项目解读">