1.添加Age、Fullname字段
esproc:
A1=now()2=file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt")3=A2.import@t()4=A3.derive(age(BIRTHDAY):Age,NAME+""+SURNAME:Fullname)5=interval@ms(A1,now())
A4:我们用T表示序表。T.derive()表示增加字段。这里用age(日期)计算出年龄,作为Age字段。用NAME,SURNAME得到Fullname。
A5:计算运算时间(interval:计算时间间隔。@ms表示以毫秒为单位)
python:
import time
import pandas as pd
import datetime
s=time.time()
data=https://www.yisu.com/zixun/pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
today=datetime.datetime.today().year
data["Age"]=today-pd.to_datetime(data["BIRTHDAY"]).dt.year
data["Fullname"]=data["NAME"]+data["SURNAME"]
print(data)
e=time.time()
print(e-s)
计算出BIETHDAY字段的值(日期)距今天的年数,作为年龄字段。用NAME+SURNAME作为Fullname字段
结果
esproc:

python:

耗时esproc0.008python0.020
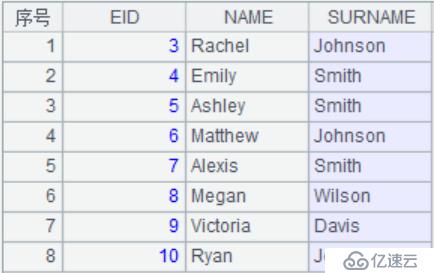
2.提取需要的记录或者字段(前3个字段,第3~10条记录)
esproc:
A1=now()2=file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt")3=A2.import@t()4=A3.new(#1,#2,#3).to(3:10)5=interval@ms(A1,now())
A4:T.new()表示新建序表。这里以第1,2,3个字段作为新表的字段。T.,表示取出序列中包含的行号。
python:
进口进口时间大熊猫作为pd
进口datetime
s=time.time ()
data=https://www.yisu.com/zixun/pd.read_csv (“C:/用户/肖恩/桌面/esproc_vs_python/EMPLOYEE.txt" , 9=“\ t" )
data=https://www.yisu.com/zixun/data.iloc [2:10, 3):
打印(数据)
e=time.time ()
打印(学位)
使用df。iloc[]切片获得3~10条记录,前三个字段(dataframe的字段号和记录号都是从0开始计数的)。
结果:
esproc:
python:

耗时esproc0.008python0.010
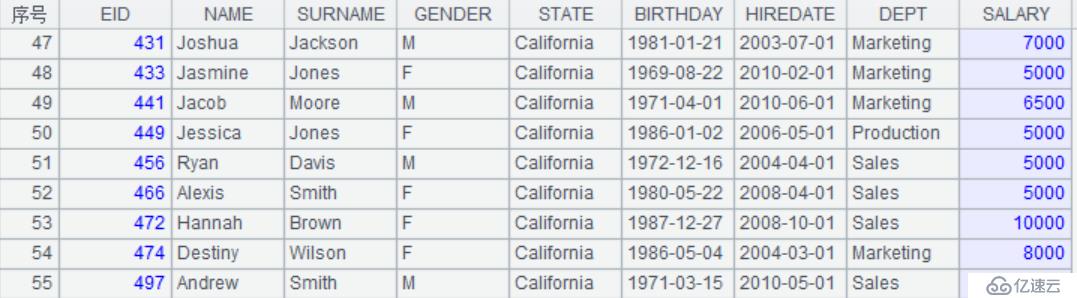
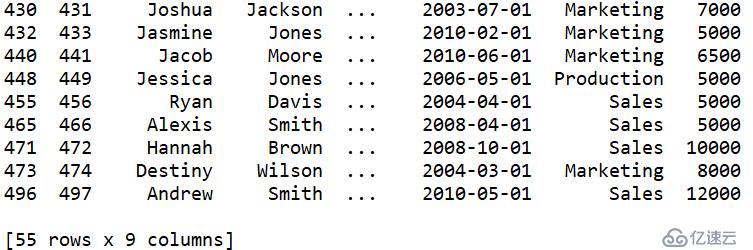
3.筛选符合条件的记录
esproc:
A1=now()2=file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt")3=A2.import@t()4=A3.select(STATE=="California")5=interval@ms(A1,now())
A4:T.select()筛选符合条件的记录。这里是筛选STATE=="California"为真的记录
python:
import time
import pandas as pd
import datetime
s=time.time()
data=https://www.yisu.com/zixun/pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
data=https://www.yisu.com/zixun/data[data['STATE']=="California"]
print(data)
e=time.time()
print(e-s)
取出data['STATE']=="California"的记录
结果:
esproc:
python:
耗时esproc0.007python0.028
4.计算字段的常用值
A1=now()2=file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt")3=A2.import@t()4=A3.min(SALARY)5=A3.max(SALARY)6=A3.avg(SALARY)7=A3.sum(SALARY)8=A3.(SALARY).median()9=A3.(float(SALARY)).variance()10=interval@ms(A1,now())
A4:T.min()计算字段最小值
A5:T.max()计算字段最大值
A6:T.avg()计算字段平均值
A7:T.sum()计算字段总和
A8:计算字段中位数。A.median(k:n)函数,参数全省略时,如果序列长度是奇数返回中间位置值;如果序列长度是偶数返回中间两个值的平均值。
A9:T.variance()计算字段方差。
python
s=time.time()
data=https://www.yisu.com/zixun/pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
min=data["SALARY"].min()
max=data["SALARY"].max()
avg=data["SALARY"].mean()
sum=data["SALARY"].sum()
median=data["SALARY"].median()
var=data["SALARY"].var()