Flink概述
Flink是Apache的一个顶级项目,Apache Flink是一个开源的分布式流处理和批处理系统.Flink的核心是在数据流上提供数据分发,通信,具备容错的分布式计算。同时,Flink在流处理引擎上构建了批处理引擎,原生支持了迭代计算,内存管理和程序优化。
现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型,因为它们所提供的SLA (Service-Level-Aggreement)是完全不相同的:流处理一般需要支持低延迟,仅一次保证,而批处理需要支持高吞吐,高效处理。
Flink从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是×××的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
Flink流处理特性:
-
<李>支持高吞吐,低延迟,高性能的流处理李
<李>支持带有事件时间的窗口(窗口)操作李
<李>支持有状态计算的仅一次语义李
<李>支持高度灵活的窗口(窗口)操作,支持基于时间,统计,会话,以及数据驱动的窗口操作李
<李>支持具有反压力功能的持续流模型李
<李>支持基于轻量级分布式快照(快照)实现的容错李
<李>一个运行时同时支持批alt="大数据框架flink与梁">
Flink以层级式系统形式组件其软件栈,不同层的栈建立在其下层基础上,并且各层接受程序不同层的抽象形式。
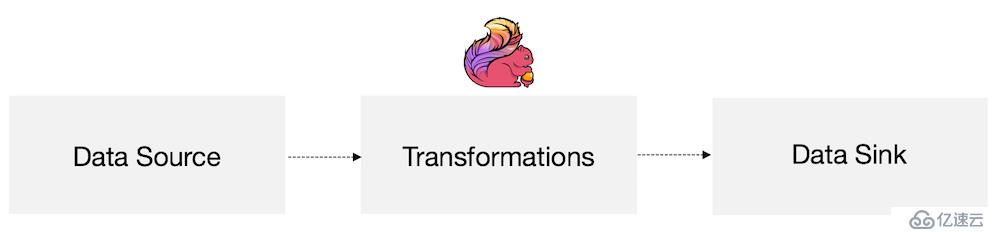
在最基本的层面上,一个Flink应用程序是由以下几部分组成:
-
<李> <>强数据来源:数据源,将数据输入到Flink中李
<李> <>强转换:处理数据李
<李> <>强数据接收器:将处理后的数据传输到某个地方李
如下图:
目前Flink支持如下框架:
-
<李> Apache卡夫卡(水槽/源)
<李> Elasticsearch 1。x/2。x/5。李x(下沉)
<李> HDFS(下沉)
<李> RabbitMQ(水槽/源)
<李>亚马逊运动流(水槽/源)
<李> Twitter(源)
<李> Apache NiFi(水槽/源)
<李> Apache Cassandra(下沉)
<李>复述、水槽和ActiveMQ(通过Apache Bahir)(下沉)
Flink官网地址如下:
http://flink.apache.org/
部分内容参考自如下文章:
https://blog.csdn.net/jdoouddm7i/article/details/62039337<人力资源/>
使用Flink完成wordcount统计
Flink下载地址:
http://flink.apache.org/downloads.html
Flink快速开始文档地址:
https://ci.apache.org/projects/flink/flink文档-释放- 1.4 -/- quickstart/setup_quickstart.html
注:安装Flink之前系统中需要安装有jdk1.7以上版本的环境
我这里下载的是2.6版本的Flink:
<代码类=" language-bash "> root@study-01 ~ # cd/usr/local/src/[root@study-01/usr/local/src] # wget http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.4.2/flink-1.4.2-bin-hadoop26-scala_2.11.tgz [root@study-01/usr/local/src] #焦油-zxvf flink-1.4.2-bin-hadoop26-scala_2.11。tgz - c/usr/local [root@study-01/usr/local/src] # cd . ./flink-1.4.2/[root@study-01/usr/local/flink-1.4.2] # ls 本设计例子自由许可日志注意选择README。三种资源的工具 [root@study-01/usr/local/flink-1.4.2] #启动Flink:
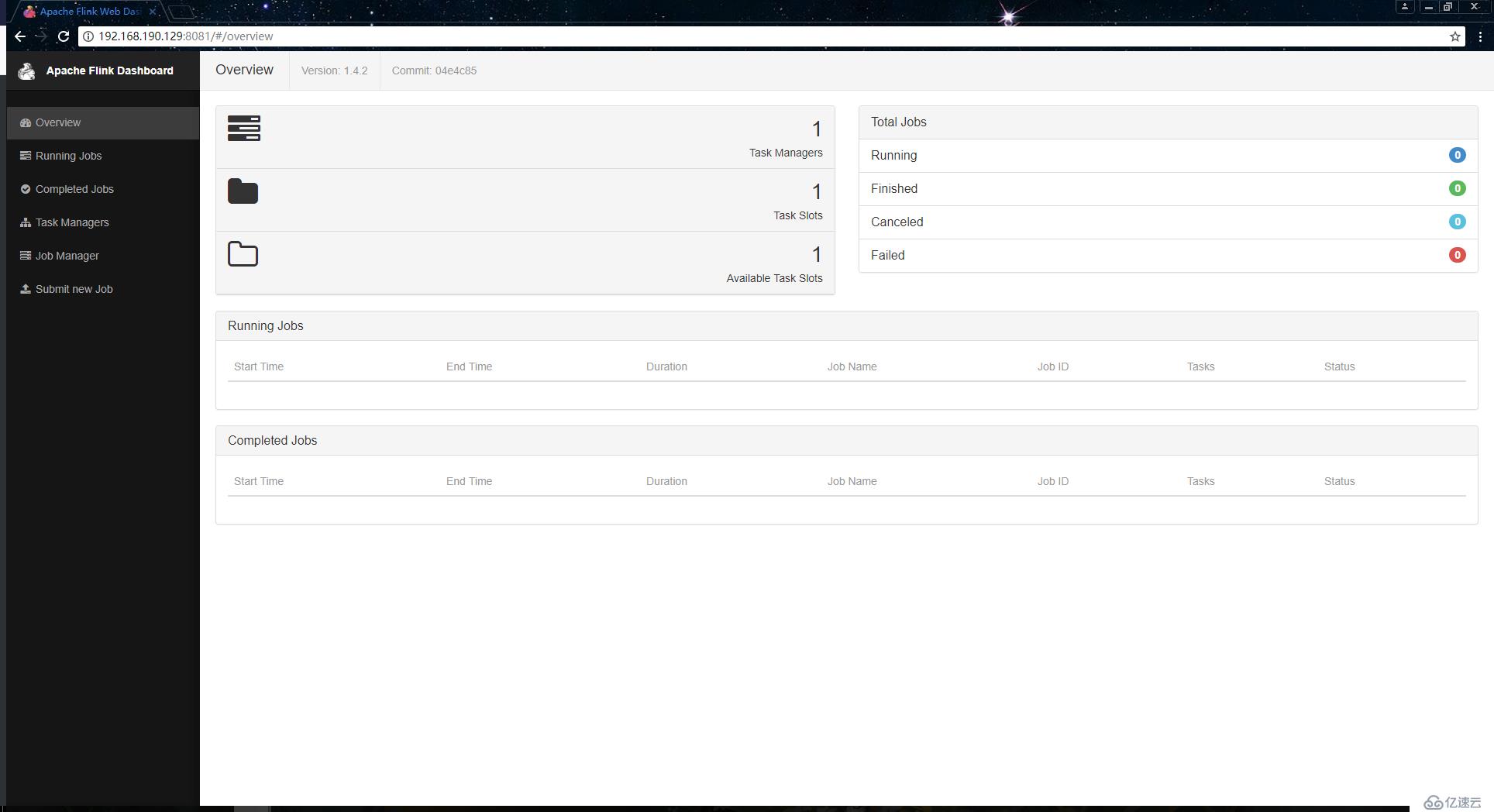
<代码类=" language-bash "> [root@study-01/usr/local/flink-1.4.2]/bin/start-local.sh # [root@study-01/usr/local/flink-1.4.2] #译本 6576年译本 6131年JobManager 6499年TaskManager [root@study-01/usr/local/flink-1.4.2] #启动成功之后就可以访问主机ip的8081端口,进入到Flink的web页面:
我们现在就可以开始实现wordcount案例了,我这里有一个文件,内容如下:
<代码类=" language-bash "> [root@study-01/usr/local/flink-1.4.2] #猫/数据/hello.txt hadoop欢迎 hadoop的hdfs mapreduce hadoop的hdfs 你好hadoop 火花和mapreduce [root@study-01/usr/local/flink-1.4.2] #执行如下命令,实现wordcount案例,如果学习过Hadoop会发现这个命令和Hadoop上使用MapReduce实现wordcount案例是类似的:
大数据框架flink与光束