,火花流的事务处理和关系型数据库的事务的概念有所不同,关系型数据库事务关注的是语句级别的一致性,例如银行转账。而引发流的事务关注的是某次工作执行的一致性。也就是如何保证工作在处理数据的过程中做到如下两点:
不丢失数据
<李>不重复处理数据
SparkStreaming程序执行架构大致如下:
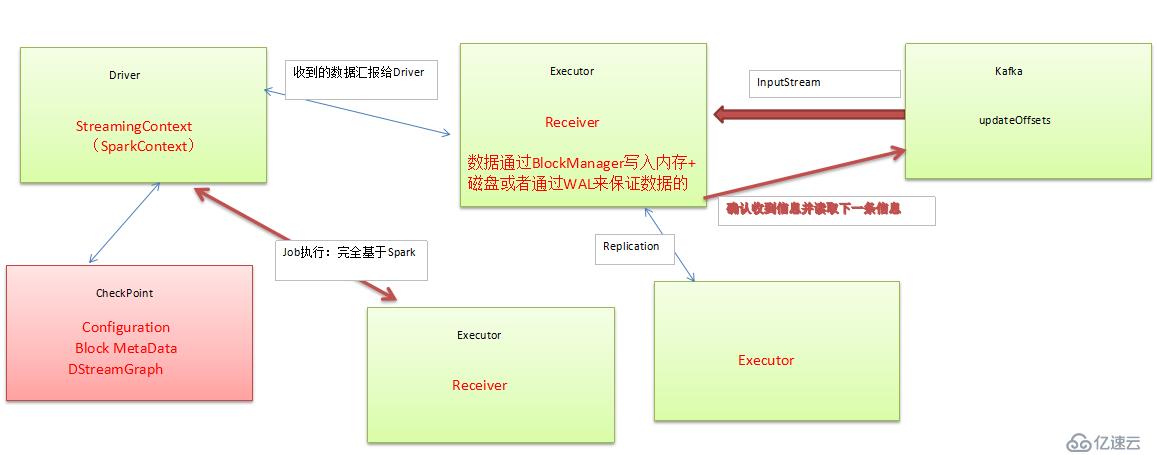
一,我们先来说说丢失数据的情况:
接收器接收到数据后,首先会在遗嘱执行人级别上保存数据(根据StorageLevel的设置),例如socketTextStream的接收器。
如果StorageLevel设置的是只进行内存级别的存储,那么当程序崩溃后,即便对司机进行了检查站,然后重新启动程序。该部分数据也会丢失。因为司机的检查点并不对计算数据进行保存。
我们假设StorageLevel设置了磁盘级别的存储,也不能完全保证数据不被丢失,因为接收机并不是接收一条数据写一次磁盘,而是按照数据块为单位写数据,然后将数据块的元数据信息发送给司机,司机的检查点记录的数块的元数据信息。当数据块写到一半的时候,或者是元数据还没有发送给司机的时候,遗嘱执行人崩溃了,数据也就丢失啦。
为了减少这种情况的发送,可以在接收机端引入细胞膜写机制,因为细胞膜写的频率要比数据块的频率高的多。这样,当执行人恢复的时候,可以读取细胞膜日志恢复数据块。
但是
1.3火花流的时候为了避免犯下的性能损失和实现完全>私人(流) class 检查点(ssc: StreamingContext,, val checkpointTime:,) extends 才能Logging with Serializable { val 才能;master =ssc.sc.master val 才能;framework =ssc.sc.appName val 才能;jars =ssc.sc.jars val 才能;graph =ssc.graph val 才能;checkpointDir =ssc.checkpointDir val 才能;checkpointDuration =ssc.checkpointDuration val 才能;pendingTimes =, ssc.scheduler.getPendingTimes .toArray () val 才能;delaySeconds =, MetadataCleaner.getDelaySeconds (ssc.conf) val 才能;sparkConfPairs =ssc.conf。getAll
其图中是DStreamGraph的实例化,它里面包含了InputDStream
我们以DirectKafkaInputDStream为例,其中包含了checkpointData
其中只是包含:
就是每个批的唯一标识时间对象,以及每个KafkaRDD对应的的卡夫卡偏移信息。
所以:
,检查点是非常高效的。没有涉及到实际数据的存储。一般大小只有几十K,因为只存了卡夫卡的偏移量等信息。
,检查点采用的是序列化机制,尤其是DStreamGraph的引入,里面包含了可能如ForeachRDD等,而ForeachRDD里面的函数应该也会被序列化。如果采用了检查点机制,而你的程序包做了做了变更,恢复后可能会有一定的问题。
二、关于数据重复处理涉及两个方面:
:在使用卡夫卡的情况下,接收器收到数据且保存到了HDFS等持久化引擎但是没有来得及进行updateOffsets,此时接收机崩溃后重新启动就会通过管理卡夫卡的动物园管理员中元数据再次重复读取数据,但是此时SparkStreaming认为是成功的,但是卡夫卡认为是失败的(因为没有更新抵消到动物园管理员中),此时就会导致数据重新消费的情况。