
这期内容当中小编将会给大家带来有关hbase与hive是怎么实现数据同步的,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
一、impala与hive的数据同步
首先,我们在hive命令行执行showdatabases;可以看到有以下几个数据库:
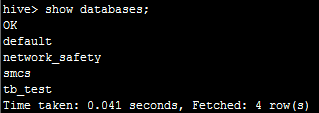
然后,我们在impala同样执行showdatabases;可以看到:
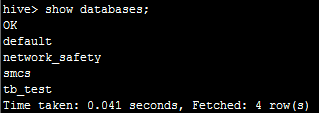
目前的数据库都是一样的。
下面,我们在hive里面执行create databaseqyk_test;创建一个数据库,如下:
然后,我们使用qyk_test这个数据库创建一张表,执行create table user_info(idbigint, account string, name string, age int) row format delimitedfields terminated by ‘\t';如下:

此时,我们已经在hive这边创建好了,然后直接在impala这边执行showdatabases;可以看到:
连qyk_test这个数据库都没有。
接下来,我们在impala执行INVALIDATEMETADATA;然后再查询可以看到:
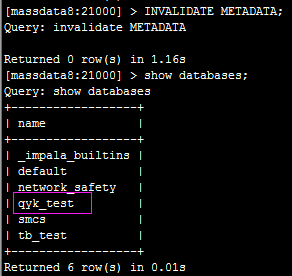
数据库和表都会同步过来。
好了,笔者来做个总结:
如果在hive里面做了新增、删除数据库、表或者数据等更新操作,需要执行在impala里面执行INVALIDATEMETADATA;命令才能将hive的数据同步impala;
如果直接在impala里面新增、删除数据库、表或者数据,会自动同步到hive,无需执行任何命令。
首先,我们在hbase中创建一张表create ‘user_sysc', {NAME=>‘info'},然后,我们在hive中执行
CREATEEXTERNALTABLEuser_sysc(keyint,valuestring)ROWFORMATSERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe' 存储的# 39;org.apache.hadoop.hive.hbase.HBaseStorageHandler& # 39; WITHSERDEPROPERTIES (& # 39; serialization.format& # 39;=& # 39; \ t # 39;, & # 39; hbase.columns.mapping& # 39;=& # 39;:关键信息:值# 39;,& # 39;field.delim& # 39;=& # 39; \ t # 39;) TBLPROPERTIES (& # 39; hbase.table.name& # 39;=& # 39; user_sysc& # 39;)
创建一张外部表指向hbase中的表,然后,我们在蜂巢执行插入tableuser_sysc选择id、名称fromuser_info;入一步份数据到user_sysc可以看到:
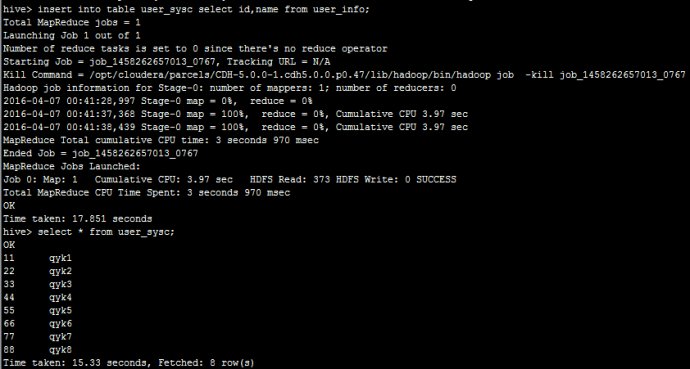
然后,我们在hbase里面执行扫描'user_sysc& # 39;可以看到:
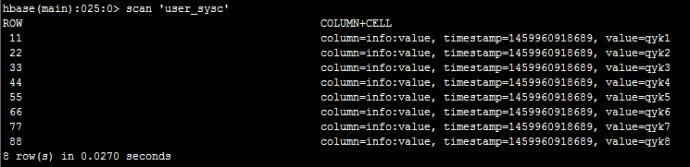
接下来,我们在hbase里面执行deleteall”user_sysc& # 39;,“11 & # 39;删掉一条数据,如下:
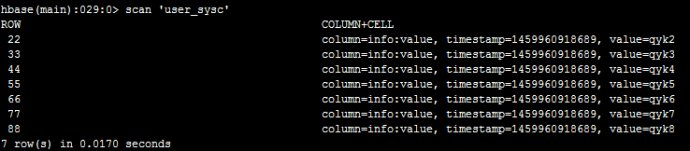
然后,我在蜂巢里面查询看看,如下:
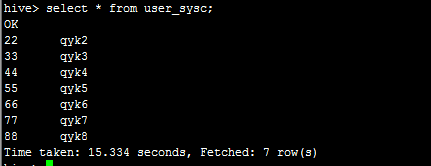
说明自动同步过来了。因此,只要创建蜂巢表时,与hbase中的表做了映射,表名和字段名可以不一致,之后无论在hbase中新增删除数据还是在蜂巢中,都会自动同步。
如果在蜂巢里面是创建的外部表需要在hbase中先创建,内部表则会在hbase中自动创建指定的表名。
上述就是小编为大家分享的hbase与蜂巢是怎么实现数据同步的了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注行业资讯频道。




