
小编给大家分享一下浏览器解析渲染HTML文档的过程是什么,希望大家阅读完这篇文章后大所收获、下面让我们一起去探讨吧!
浏览器的工作原理
一、浏览器的高层结构
浏览器的主要组件为:
1,用户界面,包括地址栏,前进/后退按钮,书签菜单等。除了浏览器主窗口显示的您请求的页面外,其他显示的各个部分都属于用户界面。
2,浏览器引擎——在用户界面和呈现引擎之间传送指令。
3,呈现引擎——负责显示请求的内容。如果请求的内容是HTML,它就负责解析HTML和CSS内容,并将解析后的内容显示在屏幕上。
4,网络,用于网络调用,比如HTTP请求。其接口与平台无关,并为所有平台提供底层实现。
5,用户界面后端,用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
6, JavaScript解释器。用于解析和执行JavaScript代码。
7、数据存储。这是持久层。浏览器需要在硬盘上保存各种数据,例如饼干。新的HTML规范(HTML5)定义了“网络数据库”,这是一个完整(但是轻便)的浏览器内数据库。
值得注意的是,和大多数浏览器不同,Chrome浏览器的每个标签页都分别对应一个呈现引擎实例。每个标签页都是一个独立的进程。
<强>二、主流程
呈现引擎一开始会从网络层获取请求文档的内容,内容的大小一般限制在8000个块以内。
然后进行如下所示的基本流程:

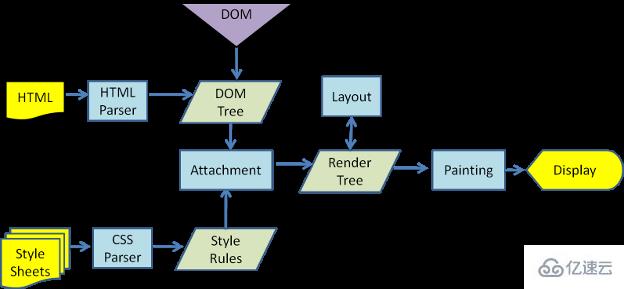
呈现引擎将开始解析HTML文档,并将各标记逐个转化成“内容树”上的DOM节点。同时也会解析外部CSS文件以及样式元素中的样式数据. HTML中这些带有视觉指令的样式信息将用于创建另一个树结构:呈现树。
呈现树包含多个带有视觉属性(如颜色和尺寸)的矩形。这些矩形的排列顺序就是它们将在屏幕上显示的顺序。
呈现树构建完毕之后,进入“布局”处理阶段,也就是为每个节点分配一个应出现在屏幕上的确切坐标。下一个阶段是绘制——呈现引擎会遍历呈现树,由用户界面后端层将每个节点绘制出来。
需要着重指出的是,这是一个渐进的过程。<强>为达到更好的用户体验,呈现引擎会力求尽快将内容显示在屏幕上。它不必等到整个HTML文档解析完毕之后,就会开始构建呈现树和设置布局。在不断接收和处理来自网络的其余内容的同时,呈现引擎会将部分内容解析并显示出来。
主流程示例:
三,处理脚本和样式表的顺序
1,脚本
网络的模型是同步的。网页作者希望解析器遇到& lt; script>标记时立即解析并执行脚本。文档的解析将停止,直到脚本执行完毕。如果脚本是外部的,那么解析过程会停止,直到从网络同步抓取资源完成后再继续。此模型已经使用了多年,也在HTML4和HTML5规范中进行了指定。作者也可以将脚本标注为“推迟”,这样它就不会停止文档解析,而是等到解析结束才执行.HTML5增加了一个选项,可将脚本标记为异步,以便由其他线程解析和执行。
2,预解析
WebKit和Firefox都进行了这项优化。<强>在执行脚本时,其他线程会解析文档的其余部分,找出并加载需要通过网络加载的其他资源。通过这种方式,资源可以在并行连接上加载,从而提高总体速度。请注意,预解析器不会修改DOM树,而是将这项工作交由主解析器处理;预解析器只会解析外部资源(例如外部脚本,样式表和图片)的引用。
3样式表
另一方面,样式表有着不同的模型。理论上来说,应用样式表不会更改DOM树,因此似乎没有必要等待样式表并停止文档解析。但这涉及到一个问题,就是脚本在文档解析阶段会请求样式信息。如果当时还没有加载和解析样式,脚本就会获得错误的回复,这样显然会产生很多问题。这看上去是一个非典型案例,但事实上非常普遍.Firefox在样式表加载和解析的过程中,会禁止所有脚本。而对于WebKit而言,仅当脚本尝试访问的样式属性可能受尚未加载的样式表影响时,它才会禁止该脚本。
4,呈现树构建
在DOM树构建的同时,浏览器还会构建另一个树结构:呈现树。这是由可视化元素按照其显示顺序而组成的树,也是文档的可视化表示。它的作用是让您按照正确的顺序绘制内容。




