
这篇文章给大家分享的是有关数据结构中散列表冲突的处理方式的内容。小编觉得挺实用的,因此分享给大家做个参考。一起跟随小编过来看看吧。
,,散列是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字键对应一个存储位置f(关键),建立了关键字与存储位置的相互对应关系,这种关系f称为散列函数(哈希函数)。

查找过程中,关键码的比较次数,取决于产生冲突的多少,产生的冲突少,查找效率就高,产生的冲突多,查找效率就低,因此,影响产生冲突多少的因素,也就是影响查找效率的因素。影响产生冲突多少有以下三个因素:
1。散列函数是否均匀;
2。处理冲突的方法;
3。散列表的装填因子。
散列表的装填因子定义为:α=填入表中的元素个数/散列表的长度
α是散列表装满程度的标志因子。由于表长是定值,α与“填入表中的元素个数”成正比,所以,α越大,填入表中的元素较多,产生冲突的可能性就越大;α越小,填入表中的元素较少,产生冲突的可能性就越小。
实际上,散列表的平均查找长度是装填因子α的函数,只是不同处理冲突的方法有不同的函数。
解决哈希冲突的方法一般有:
第一开放定址法
所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找的到,并将记录存入。
公式:f(关键)=(f(键)+ di) % m (di=1、2、3….m-1)
比如说,关键字集合为{67、56、16,25岁,37岁,22日,29日,15日,47岁,48岁,34},表长为12。散列函数f(关键)=关键国防部12。
当计算前5个数{67、56、16、25}时,都是没有冲突的散列地址,直接存入;计算关键=37时,发现f(37)=1,此时就与25所在的位置冲突。于是应用上面的公式f (37)=(f(37) + 1)国防部12=2。于是将37存入下标为2的位置。接下来22日,29日,15日,47个都没有冲突,正常的存入。到了48岁的计算得到f(48)=0,与12所在的0位置冲突了,不要紧,我们f (48)=(f(48) + 1)国防部12=1,此时又与25所在的位置冲突。于是f (48)=(f(48) + 2)国防部12=2,还是冲突……一直到f (48)=(f(48) + 6)国防部12=6时,才有空位,如下表所示。
序号01234567891011关键字12256756
2号再哈希法
对于散列表来说,可以事先准备多个散列函数。
公式:RHi fi(关键)=(关键)(i=1、2、3…, k)
这里奥镁就是不同的散列函数,可以把除留余数,折叠,平方取中全部用上。每当发生散列地址冲突时,就换一个散列函数计算。
这种方法能够使得关键字不产生聚集,但相应地也增加了计算的时间。
。3链地址法(拉链法)
将所有关键字为同义词的记录存储在一个单链表中,称这种表为同义词子表,在散列表中只存储所有同义词子表前面的指针。对于关键字集合{67、56、16,25岁,37岁,22日,29日,15日,47岁,48岁,34},用前面同样的12为余数,进行除留余数法,可以得到下图结构。
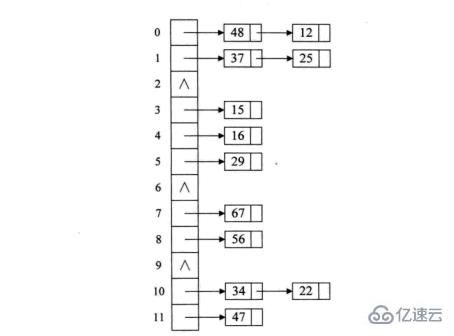
。4建立公共溢出区
这个方法是当你时重新给你找个地址,为所有冲突的关键字建立一个公共的溢出区来存放。
就前面的例子而言,共有三个关键字37岁,48岁,34与之前的关键字位置有冲突,那就将它们存储到溢出表中。如下图所示。
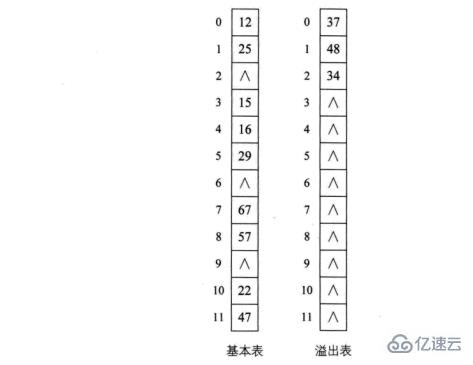
在查找时,对给定值通过散列函数计算出散列地址后,先与基本表的相应位置进行比对,如果相等,则查找成功,如果不相等,则到溢出表中进行顺序查找。如果相对于基本表而言,有冲突的数据很少的情况下,公共溢出区的结构对查找性能来说还是非常高的。
感谢各位的阅读!关于数据结构中散列表冲突的处理方式就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到吧!




