
本篇文章为大家展示了MySql数据库中实现主从复制的原理是什么,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
数据库读写分离对于大型系统或者访问量很高的互联网应用来说,是必不可少的一个重要功能。对于MySql来说,标准的读写分离是主从模式,一个写节点主后面跟着多个读节点,读节点的数量取决于系统的压力,通常是1 - 3个读节点的配置。而一般的读写分离中间件,例如字符集的读写分离和自动切换机制,需要MySql的主从复制机制配合。
<强>主从配置需要注意的地方
1,主数据库服务器和从DB服务器数据库的版本一致
2,主数据库服务器和从DB服务器数据库数据名称一致
3,主数据库服务器开启二进制日志,主数据库服务器和从数据库服务器的server_id都必须唯一MySql主服务器配置
第一步:修改我的。参看文件:
在(mysqld)段下添加:
第二步:重启mysql服务服务mysql
第重启三步:建立帐户并授权奴隶
mysql>格兰特文件> mysql>, show master 地位; + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - + + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - + |,File ,,,,,, |, Position |, Binlog_Do_DB |, Binlog_Ignore_DB | Executed_Gtid_Set | + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - + + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - + | |,mysql-bin.000001 ,, 881, |,,,,,,, |, mysql ,,,,, |,,,,,,,,, | + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - + + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - + 1,row set 拷贝;(0.00,sec)
MySQL从服务器配置
第一步:修改my.conf文件
(mysqld) #从服务器唯一ID,一般取IP最后一段服务器ID=83
第二步:配置从服务器
mysql>修改主master_host=& # 39; 192.168.11.82& # 39;, master_port=3306, master_user=& # 39;奴隶# 39;,master_password=& # 39; slavepw& # 39;, master_log_file=& # 39; mysql-bin.000001& # 39;, master_log_pos=881;
注意语句中间不要断开,master_port为MySQL服务器端口号(无引号),master_user为执行同步操作的数据库账户,“881”无单引号(此处的881就是显示主状态中看到的位置的值,这里的mysql-bin.000001就是文件对应的值)。
第三步:启动从服务器复制功能
mysql>开始奴隶;
第四步:检查从服务器复制功能状态:
mysql>show slave status;
Slave_IO_Running: Yes//此状态必须YES
Slave_SQL_Running: Yes//此状态必须YES
注:Slave_IO及Slave_SQL进程必须正常运行,即YES状态,否则都是错误的状态(如:其中一个NO均属错误)。
进行验证
在主节点上创建表、插入数据,发现从节点也创建表并插入数据。
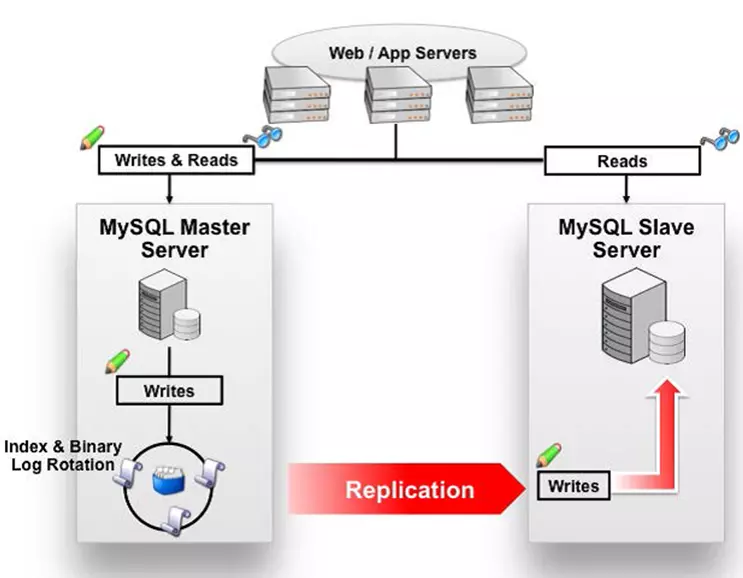
MySQL 主从复制原理的是啥?
主库将变更写入 binlog 日志,然后从库连接到主库之后,从库有一个 IO 线程,将主库的 binlog 日志拷贝到自己本地,写入一个 relay 中继日志中。接着从库中有一个 SQL 线程会从中继日志读取 binlog,然后执行 binlog 日志中的内容,也就是在自己本地再次执行一遍 SQL,这样就可以保证自己跟主库的数据是一样的。
这里有一个非常重要的一点,就是从库同步主库数据的过程是串行化的,也就是说主库上并行的操作,在从库上会串行执行。所以这就是一个非常重要的点了,由于从库从主库拷贝日志以及串行执行 SQL 的特点,在高并发场景下,从库的数据一定会比主库慢一些,是有延时的。所以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
而且这里还有另外一个问题,就是如果主库突然宕机,然后恰好数据还没同步到从库,那么有些数据可能在从库上是没有的,有些数据可能就丢失了。
所以 MySQL 实际上在这一块有两个机制,一个是半同步复制,用来解决主库数据丢失问题;一个是并行复制,用来解决主从同步延时问题。
MySql数据库中实现主从复制的原理是什么




