
介绍 import 请求
得到lxml import etree
import xlwt
import 时间
,
headers =, {
,,,,,,& # 39;用户代理# 39;:,& # 39;Mozilla/5.0, (Windows NT 10.0;, Win64;, x64), AppleWebKit/537.36, (KHTML, like 壁虎),chrome # 39;
,,,,,,,,,,,,,,,,,,,,& # 39;/70.0.3538.110 Safari/537.36 & # 39;
}
时间=all_info_list []
,
,
def get_photo (url):
,,,res =, requests.get (url,头=标题)
,,,selector =, etree.HTML (res.text)
,,,divs =, selector.xpath (& # 39;//div [@class=發ist_con"] & # 39;)
,,,for div 拷贝div:
,,,,,,,names =, div.xpath (& # 39; div [2]/h4/text () & # 39;) [0] .strip ()
,,,,,,,types =, div.xpath (& # 39; div [2]/p [1]/text () [1] & # 39;) [0]
,,,,,,,area =, div.xpath (& # 39; div [2]/p [1]/text () [2] & # 39;) [0]
,,,,,,,direction =, div.xpath (& # 39; div [2]/p [1]/text () [3] & # 39;) [0]
,,,,,,,price =, div.xpath (& # 39; div [2]/div/p/text () & # 39;) [0]
,,,,,,,info_list =,(名称,类型,,,,,,价格)
,,,,,,,all_info_list.append (info_list)
,,,time . sleep (1)
,
,
if __name__==& # 39; __main__ # 39;:
,,,urls =, (& # 39; https://m.5i5j.com/bj/zufang/index-_%E6%9C%9B%E4%BA%AC/n {} & # 39; .format (str (i)), for 小姐:拷贝范围(1、4)]
,,,for url 拷贝网址:
,,,,,,,get_photo (url)
,,,xls_header =,(& # 39;地点& # 39;,,& # 39;户型& # 39;,,& # 39;面积& # 39;,,& # 39;朝向& # 39;,,& # 39;价格& # 39;】
,
,,,book =, xlwt.Workbook(编码=& # 39;utf - 8 # 39;)
,,,sheet =, book.add_sheet (& # 39; 5 i5j& # 39;)
,,,for h 拷贝范围(len (xls_header)):
,,,,,,,sheet.write (0 h xls_header [h])
,,,小姐:=1
,,,for list 拷贝all_info_list:
,,,,,,,j =0
,,,,,,,for data 拷贝列表:
,,,,,,,,,,,sheet.write (i, j,数据)
,,,,,,,,,,,j +=1
,,,,,,,小姐:+=1
,,,book.save (& # 39; 5 i5j.xls& # 39;)
这篇文章主要介绍了怎么绕过python反爬虫获取租房信息,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获。下面让小编带着大家一起了解一下。
python爬虫试了一下,但是遇到了反爬虫的阻拦,不过最终还是通过修改代码解决了。接下来我们就一起看看绕过python反爬虫获取租房信息的方法吧。
在有的页面后面会出现一段代码,通过禁用浏览器JavaScript发现每页其实初始界面是一段JS代码,然后跳转至目标页
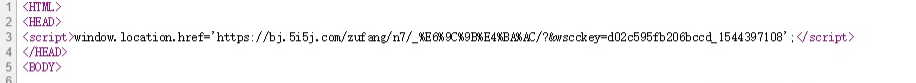
,
百度了一下这种反爬虫的绕过措施都是python加载JS代码,自己感觉比较麻烦就没有实施,但是在查看网页源代码时发现了下面这段代码,其目的应该是检测到移动端跳转至移动端网页

,
既然使用了Ajax,抓包抓一下浏览时传输的数据就得到了下面的URL
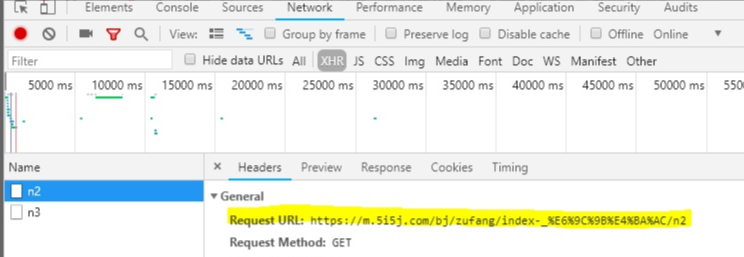
,
上图黄色画出的就是每次向下浏览加载的页面,通过修改后面的数字可以定位不同的页面,构造URL,那么剩下的就是爬取数据了,下面贴一下简略代码
感谢你能够认真阅读完这篇文章,希望小编分享怎么绕过python反爬虫获取租房信息内容对大家有帮助,同时也希望大家多多支持,关注行业资讯频道,遇到问题就找,详细的解决方法等着你来学习!




