
介绍 #,- *安康;编码:utf-8 - * -
import 请求
import json
得到urllib.request import urlretrieve
,
headers =,{& # 39;授权# 39;:& # 39;Bearer Mi4xQXN3S0F3QUFBQUFBUUVJSjdTempDaGNBQUFCaEFsVk5BQzRmV3dDVVJzeU9NOWxNU0pZT1BNdFJ5bTlrSzk3MU1B | 1513218048 | 1 e03f7e7f26825482a72e4a629ef80292847548e& # 39;,
,,,,,,,,,,& # 39;用户代理# 39;:& # 39;Mozilla/5.0, (Windows NT 6.1;, WOW64), AppleWebKit/537.36, (KHTML, like 壁虎),Chrome/55.0.2883.87 Safari/537.36 & # 39;
,,,,,,,,,,& # 39;x-udid& # 39;: & # 39; AEBCCe0s4wqPToZZF6LV3roAjT8uEikZF1k=& # 39;
,,,,,,,,,,},,,#请求头
时间=urls [& # 39; https://www.zhihu.com/api/v4/members/feifeimao/followers?include=data%5B * % 5 d.answer_count % 2 carticles_count % 2 cgender % 2 cfollower_count % 2 cis_& # 39;, \
,,,,,& # 39;随后% 2 cis_following % 2 cbadge % 5 b % 3 f(类型% 3 dbest_answerer) % 5 d.topics&抵消={},限制=20 & # 39;.format(我* 20),for 小姐:拷贝range (0 5)]
时间=img_urls [],,, #用来存所有的img_url
for url url拷贝:
,,,datas =, requests.get (url, headers =,头). json()(& # 39;数据# 39;],,,#获取json文件下的数据
,,,for it 拷贝数据:
,,,,,,,img_url =,它[& # 39;avatar_url& # 39;],,, #获取头像url
,,,,,,,img_urls.append (img_url),,,,,, #把获取的url依次放入img_urls
,
,,,小姐:=,0,,,#计数
,,,for it 拷贝img_urls:
,,,,,,,urlretrieve (, & # 39; D://% s.jpg& # 39;, %, i),,, #通过url,依次下载头像,并保存于D盘
,,,,,,,小姐:=,+ 1,,,#我依次累加
这篇文章将为大家详细讲解有关用python爬虫收集知乎V头大像的示例,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
<强>
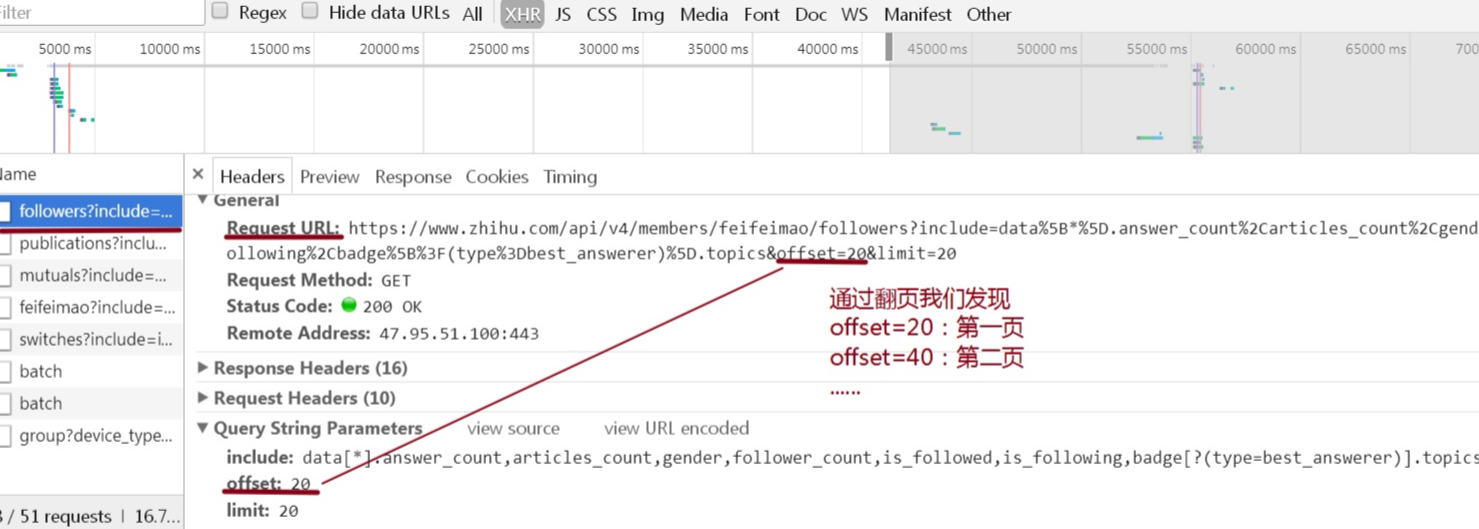
url并非url需要我们通过抓包获取,流程如图:
url:
url中开始随之同步变化,变化的间隔为20,即抵消=20(第一页),开始=40(第二页),以此类推,所以我们得出.format(我* 20),大家可以对比第三篇的翻页。
img_url
json
。text是需要网页返回文本的信息,而这里返回的是json文件,所以用。json
关于用python爬虫收集知乎V头大像的示例就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看的到。




