
介绍
利用Python怎么样实现一个并发爬虫?很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
<强>一。顺序抓取
顺序抓取是最最常见的抓取方式,一般初学爬虫的朋友就是利用这种方式、下面是一个测试代码,顺序抓取8个url,我们可以来测试一下抓取完成需要多少时间:
头={& # 39;接受# 39;:& # 39;text/html, application/xhtml + xml, application/xml; q=0.9 & # 39;,
& # 39;接收语言# 39;:& # 39;应用,zh型;q=0.8 & # 39;
& # 39;Accept-Encoding& # 39;: & # 39; gzip、缩小# 39;}
url=[& # 39; http://www.cnblogs.com/moodlxs/p/3248890.html& # 39;
& # 39;https://www.zhihu.com/topic/19804387/newest& # 39;
& # 39;http://blog.csdn.net/yueguanghaidao/article/details/24281751& # 39;
& # 39;https://my.oschina.net/visualgui823/blog/36987& # 39;
& # 39;http://blog.chinaunix.net/uid - 9162199 - id - 4738168. - html # 39;,
& # 39;http://www.tuicool.com/articles/u67Bz26& # 39;
& # 39;http://rfyiamcool.blog.51cto.com/1030776/1538367/& # 39;
& # 39;http://itindex.net/detail/26512-flask-tornado-gevent& # 39;]
# url为随机获取的一批url
def func ():
“““
顺序抓取
“““
进口的要求
导入的时间
url=url
头=头
标题(& # 39;用户代理# 39;]=癕ozilla/5.0 + (Windows +元+ 6.2;+ WOW64) + AppleWebKit/537“;\
“36 + (KHTML, + +壁虎)+铬/45.0.2454.101 + Safari/537.36”;
print (u # 39;顺序抓取& # 39;)
开始时间=time.time ()
为在url网址:
试一试:
r=请求。get (url, allow_redirects=False,超时=2.0,标题=标题)
除了:
通过
其他:
打印(r。status_code r.url)
endtime=time.time ()
打印(endtime-starttime)
func () 我们直接采用内建的time.time()来计时,较为粗略,但可以反映大概的情况下。面是顺序抓取的结果计时:
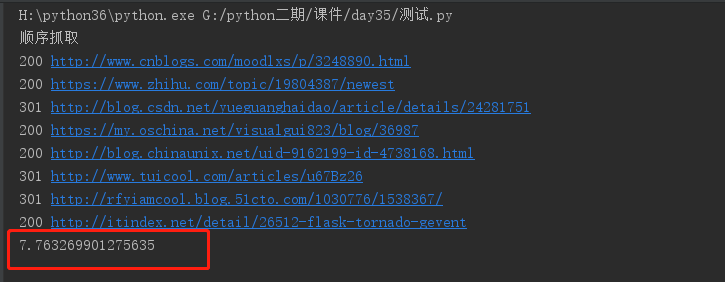
可以从图片中看到,显示的顺序与url的顺序是一模一样的,总共耗时为7.763269901275635秒,一共8个url,平均抓取一个大概需要0.97秒。总体来看,还可以接受。
<强>二。多线程抓取
线程是python内的一种较为不错的并发方式,我们也给出相应的代码,并且为每个url创建了一个线程,一共8线程并发抓,取下面的代码:
下面是我们运行8线程的测试代码:
头={& # 39;接受# 39;:& # 39;text/html, application/xhtml + xml, application/xml; q=0.9 & # 39;,
& # 39;接收语言# 39;:& # 39;应用,zh型;q=0.8 & # 39;
& # 39;Accept-Encoding& # 39;: & # 39; gzip、缩小# 39;}
url=[& # 39; http://www.cnblogs.com/moodlxs/p/3248890.html& # 39;
& # 39;https://www.zhihu.com/topic/19804387/newest& # 39;
& # 39;http://blog.csdn.net/yueguanghaidao/article/details/24281751& # 39;
& # 39;https://my.oschina.net/visualgui823/blog/36987& # 39;
& # 39;http://blog.chinaunix.net/uid - 9162199 - id - 4738168. - html # 39;,
& # 39;http://www.tuicool.com/articles/u67Bz26& # 39;
& # 39;http://rfyiamcool.blog.51cto.com/1030776/1538367/& # 39;
& # 39;http://itindex.net/detail/26512-flask-tornado-gevent& # 39;]
def线程():
从线程进口线程
进口的要求
导入的时间
url=url
头=头
标题(& # 39;用户代理# 39;]=癕ozilla/5.0 + (Windows +元+ 6.2;+ WOW64) + AppleWebKit/537.36 +“;\
“(KHTML, + +壁虎)+ Chrome/45.0.2454.101 + Safari/537.36“;
def (url):
试一试:
r=请求。get (url, allow_redirects=False,超时=2.0,标题=标题)
除了:
通过
其他:
打印(r。status_code r.url)
print (u # 39;多线程抓取& # 39;)
ts=[线程(目标=,arg游戏=(url))的url网址)
开始时间=time.time ()
在ts t:
t.start ()
在ts t:
t.join ()
endtime=time.time ()
打印(endtime-starttime)
线程() 多线程抓住的时间如下:
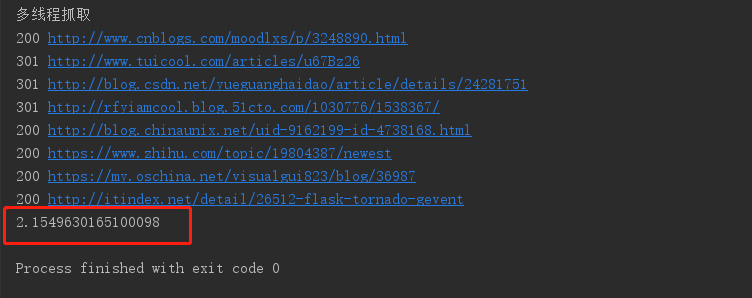
可以看到相较于顺序抓取,8线程的抓取效率明显上升了3倍多,全部完成只消耗了2.154秒。可以看到显示的结果已经不是url的顺序了,说明每个url各自完成的时间都是不一样的。线程就是在一个进程中不断的切换,让每个线程各自运行一会,这对于网络io来说,性能是非常高的。但是线程之间的切换是挺浪费资源的。




