
介绍 #,构造全2019年的月份列表
时间=months []
for year 拷贝(2019年):
,,,for month 拷贝范围(12):
,,,,,,,months.append (“% d % 02 d" % + 1(年,月)
todo_urls =, (
,,,“http://tianqi.2345.com/t/wea_history/js/" +月+“/58457 _" +月+“.js"
,,,for month 拷贝
) import 请求
时间=datas []
for url todo_urls拷贝:
,,,r =, requests.get (url, headers =,标题)
,,,if r.status_code !=200:
,,,,,,,raise 异常()
,,,#,去除javascript前后的字符串,得到一个js格式的JSON
,,,data =, r.text.lstrip (“var weather_str=? .rstrip (“;”)
datas.append(数据) #,解析所有月份的数据
时间=all_datas []
,
for data 拷贝数据:
,,,tqInfos =, demjson.decode(数据)(“tqInfo")
all_datas.extend ([x for x 拷贝tqInfos if len (x)在0]) import csv
with 开放(& # 39;。/hangzhou_tianqi_2019.csv& # 39;,, & # 39; w # 39;,,换行符=& # 39;& # 39;,,编码=& # 39;utf - 8 # 39;), as csv_file:
,,,writer =, csv.writer (csv_file)
,,,columns =,列表(all_datas [0] . keys ())
,,,writer.writerow(列)
,,,,
,,,for data 拷贝all_datas:
,,,,,,,writer.writerow([数据(列),for column 拷贝列])
小编给大家分享一python爬下虫如何爬取天气预报表,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获、下面让我们一起去了解一下吧!
Javascript文件获取的,因此,我们需要构造带爬取数据的URL列表,再批量爬取数据。
请求库获取js文件中的数据,并存到数据变量中。
js文件获取的数据json格式存储的,需要使用demjson对数据进行解析。
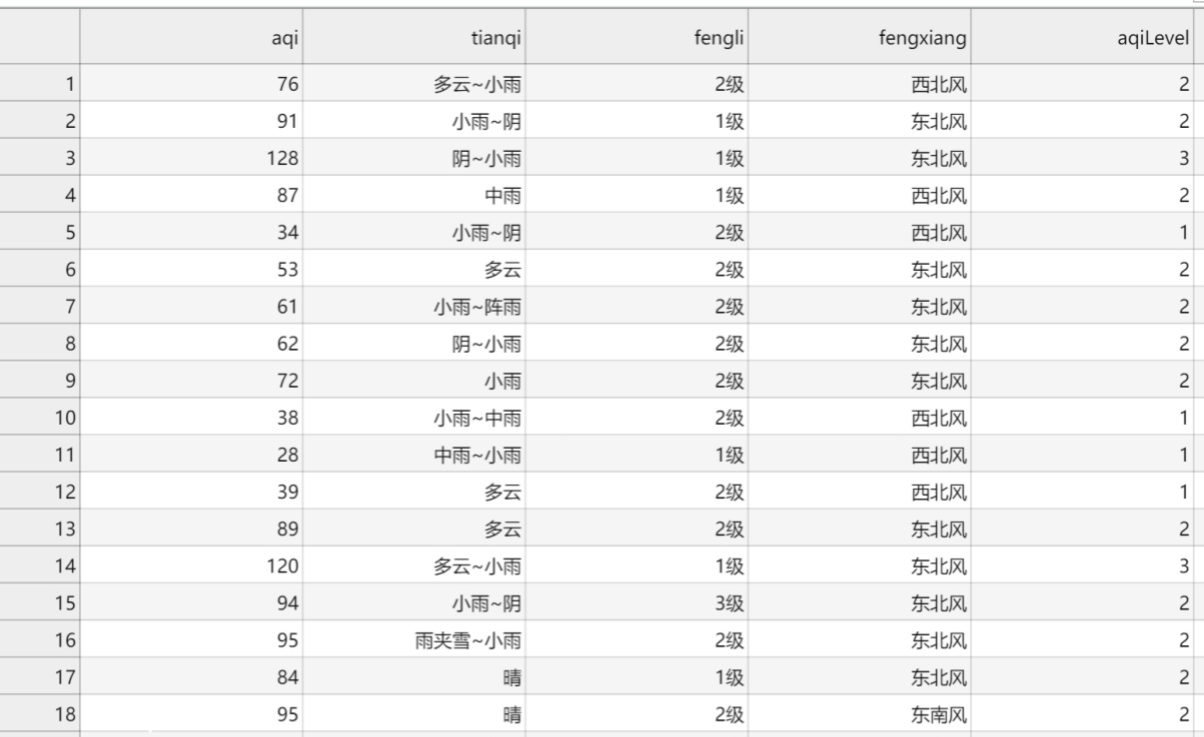
以上是python爬虫如何爬取天气预报表的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注行业资讯频道!




