介绍
本篇文章为大家展示了利用python如何实现一个解析protobuf文件功能,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
<强>厚度使用
<强>简介
如果你不是从事编译器或者解析器的开发工作,你可能从未听说过ply.ply是基于python的lex和yacc,而它的作者就是大名鼎鼎python食谱,第3版的作者。可能有些朋友就纳闷了,我一个业务开发怎么需要自己写编译器呢,各位编程大牛说过,中央决定了,要多尝试新的东西,而且了解一些语法解析的姿势,以后自己解析格式复杂的日志或者数学公式,也是非常有帮助的。
针对没有编译基础的童鞋,强烈建议了解一些文法相关的基本概念。轮子哥强烈推荐的解析技术以及编译龙虎鲸书,个人感觉都不适合入门学习,在此推荐胡伦俊的编译原理(电子工业出版社),针对概念的例子讲解很多,很适合入门学习。当然也不需要特别深入研究,知道词法分析和语法分析的相关概念和方法就可以愉快的使用厚度了。文档链接:http://www.pchou.info/open-source/2014/01/18/52da47204d4cb.html
为了方便大家上的手,以求解多元一次方程组为例,讲解一下厚度的使用。
<强>例子说明
输入是多个格式为x 3.2 + 4 y - z=7的一次方程,为了让例子尽可能简单,做如下限制:
<李>每个方程含有变量的部分在等号左边,常数在等号右边李 <李>每个方程不限制变量的个数以及变量的顺序,但每个方程每个变量只允许出现一次李 <>李变量的命令规则为小写字母串(x y xx yy abc均为合法变量名) <李>变量的系数限制为整数和浮点数,浮点数不允许1.4 e8的格式,系数和变量紧邻,且系数不能为0 <李>方程组和方程组之间用,;隔开
李,
学过线性代数的童鞋肯定知道,只需要将方程组抽象为矩阵,按照线性代数的方法就可以解决。因此只需要将输入方程组解析成右边的矩阵和变量列表即可,剩下的求解过程就可以交给线性代数相关的工具解决。
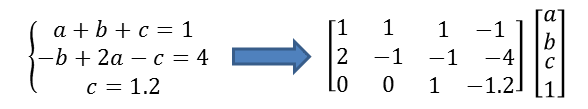
<强>词法解析
厚度中的lex来做词法解析,词法解析的理论有一大堆,但是lex用起来却非常直观,就是用正则表达式的方式将文本字符串解析为一个一个的令牌,下面的代码就是用lex实现词法解析。
#空格制表符回车这些不可见符号都忽略
t_ignore=& # 39;\ \ " t # 39;
#解析错误的时候直接抛出异常
def t_error (t):
提高异常(& # 39;错误{}在{}行& # 39;.format (t。价值[0],t.lineno))
#记录行号,方便出错定位
def t_newline (t):
" # 39;\ n + & # 39;
t.lexer。lineno +=len (t.value)
#支持c++风格的\ \注释
def t_ignore_COMMENT (t):
" # 39;\/\/[^ \ n] * & # 39;
#变量的命令规则
def t_VARIABLE (t):
" # 39;[a - z] + & # 39;
返回t
#常数命令规则
def t_CONSTANT (t):
" # 39;\ d + (\ \ d +), # 63; & # 39;
t。值=https://www.yisu.com/zixun/float (t.value)
返回t
#输入中支持的符号头令牌,当然也支持t_PLUS=r/+”的方式将加号定义为令牌
文字=' + -,='
令牌=(“变量”,“常数”)
if __name__==癬_main__”:
data=?
2.4 - x + y + z=0;//这是一个评论
9 y - z + 7.2 x=1;
y - z + x=8
“‘
词法分析程序=lex.lex ()
lexer.input(数据)
而真正的:
托托=lexer.token ()
如果不是托托:
打破
打印托托 直接运行文件就可以将解析的令牌串打印出来,如下所示,详细的使用文档可以参考厚度文档。
LexToken (- & # 39; & # 39;, 2、5)
LexToken(变量,& # 39;x # 39;, 2, 6)
LexToken (+ & # 39; + & # 39;, 2, 8)
LexToken(常数,2.4,2,10)
LexToken(变量,& # 39;y # 39;, 2, 13)
LexToken (+ & # 39; + & # 39;, 2、15)
LexToken(变量,& # 39;z # 39;, 2, 17)
LexToken (=& # 39;=& # 39;, 2、19)
LexToken(常数,0.0,2,21)
LexToken (& # 39;;; & # 39;, 2、22) ' ' '
# # #语法解析
厚度中的yacc用作语法分析,虽然复杂的词法分析可以代替简单的语法分析,但类似于编程语言的解析再复杂的词法分析也胜任不了。在使用yacc之前,需要了解上下文无关文法,这部分内容太多太杂,我也只了解部分简单的概念,有兴趣的可以看一看编译原理深入了解。
目前语法分析的方法有两大类,即自下向上的分析方法和自上而下的分析方法。所谓自上而下的分下法就是从文法的开始符号出发,根据文法规则正向推到出给定句子的一种方法,或者说,从树根开始,往下构造语法树,直到建立每个树叶的分析方法。代表算法是LL(1),此算法文法解析能力不强,对文法定义要求比较高,主流的编译器都没有使用。自下而上的分析法是从给定的输入串开始,根据文法规则逐步进行归约,直至归约到文法的开始符号,或者说从语法书的末端开始,步步向上归约,直至归约到根节点的分析方法。代表算法有单反,LRLR,厚度使用的就是LRLR。
因此我们只需要定义文法和规约动作即可,以下就是完整的代码。
”“python
# - * -=utf8编码- * -
从进口厚度(
lex,
yacc
)
#空格制表符回车这些不可见符号都忽略
t_ignore=& # 39;\ \ " t # 39;
#解析错误的时候直接抛出异常
def t_error (t):
提高异常(& # 39;错误{}在{}行& # 39;.format (t。价值[0],t.lineno))
#记录行号,方便出错定位
def t_newline (t):
" # 39;\ n + & # 39;
t.lexer。lineno +=len (t.value)
#支持c++风格的\ \注释
def t_ignore_COMMENT (t):
" # 39;\/\/[^ \ n] * & # 39;
#变量的命令规则
def t_VARIABLE (t):
" # 39;[a - z] + & # 39;
返回t
#常数命令规则
def t_CONSTANT (t):
" # 39;\ d + (\ \ d +), # 63; & # 39;
t。值=https://www.yisu.com/zixun/float (t.value)
返回t
#输入中支持的符号头令牌,当然也支持t_PLUS=r/+”的方式将加号定义为令牌
文字=' + -,='
令牌=(“变量”,“常数”)
#顶层文法、规约的时候方程对应的p[1]是一个列表,包含了方程左边各个变量与系数还有方程左边的常数
def p_start (p):
开始:方程”“”“
var_count var_list=0, []
离开,_ p [1]:
反对,var_name左:
如果var_name var_list:
继续
var_list.append (var_name)
var_count +=1
矩阵=[[0]* (var_count + 1) _的xrange (len (p [1])))
计数器,情商在列举(p [1]):
左、右=情商
反对,var_name左:
矩阵[计数器][var_list.index (var_name)]=反对
矩阵(柜台)[1]=-对
var_list.append (1)
p[0]=矩阵,var_list
#方程组对应的文法,每个方程用,或者;做分隔
def p_equations (p):
”““方程:方程,方程
|方程“;”方程
|方程”“”
如果len (p)==2:
p [0]=[p [1]]
其他:
p [0]=[p [1]] + p [3]
#单个方程对应的文法
def p_equation (p):
”““方程:eq_left‘=痚q_right”“
p [0]=(p[1],[3]页)
#方程等式左边对应的文法
def p_eq_left (p):
”““eq_left: var_unit eq_left
|”“”
如果len (p)==1:
p [0]=[]
其他:
p [0]=[p [1]] + p [2]
#六种文法对应例子:x, x 5 + x - x, 4 + 4 x, y
#归约的形式是一个元组,例:(5,“x”)
def p_var_unit (p):
”““var_unit:变量
|常数变量
|“+”变量
|”——“变量
|“+”常数变量
| -常数变量”“”
len_p=len (p)
如果len_p==2:
p [0]=(1.0, p [1])
elif len_p==3:
如果p [1]==?”:
p [0]=(1.0, p [2])
elif p [1]==?”:
p [0]=(-1.0, p [2])
其他:
p [0]=(p[1],[2]页)
其他:
如果p [1]==?”:
p [0]=(p[2],[3]页)
其他:
p [0]=(- p[2],[3]页)
#方程等式右边对应的常数,对应的例子:1.2,+ 1.2,-1.2
def p_eq_right (p):
”““eq_right:常数
|“+”常数
|”——“常数”“”
如果len (p)==3:
如果p [1]==?”:
p [0]=- p [2]
其他:
p [0]=[2]
其他:
p [0]=[1]
if __name__==癬_main__”:
data=?
null
null
null
null
null
null
null
null
null
null





