
介绍
今天就跟大家聊聊有关bilibili视频如何利用python进行下载,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
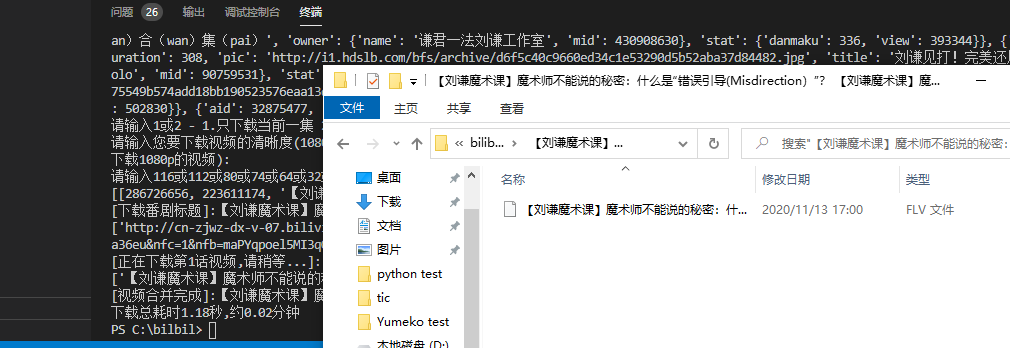
<强>运行效果:
<强>完整代码
# !/usr/bin/python
# - * -编码:utf - 8 - *
#时间:2019/07/21——20:12
__author__=& # 39;亨利和# 39;
& # 39;& # 39;& # 39;
项目:B站动漫番剧(bangumi)下载
版版本2:无加密的API,但是需要加入登录后饼干中的SESSDATA字段,才可下载720 p及以上视频
API:
1.获取cid的api为https://api.bilibili.com/x/web-interface/view& # 63;援助=47476691援助后面为av号
2.下载链接api为https://api.bilibili.com/x/player/playurl& # 63;狂热的=44743619,cid=78328965, qn=32 cid为上面获取到的热心为输入的av号qn为视频质量
注意:
但是此接口头需要加上登录后& # 39;饼干# 39;:& # 39;SESSDATA=https://www.yisu.com/zixun/3c5d20cf%2C1556704080%2C7dcd8c41 '(30天的有效期)(因为现在只有登录后才能看到720 p以上视频了)
不然下载之后都是最低清晰度,哪怕选择了80也是只有480 p的分辨率! !
“‘
导入请求,时间,urllib。要求,再保险
从moviepy。编辑器进口*
进口操作系统、系统线程,json
进口imageio
#访问API地址
def get_play_list(援助,cid,质量):
url_api=' https://api.bilibili.com/x/player/playurl& # 63; cid={}狂热={}qn={} ' .format (cid、援助、质量)
头={
“用户代理”:“Mozilla/5.0 (Windows NT 6.1;AppleWebKit WOW64)/537.36 (KHTML,像壁虎)Chrome/55.0.2883.87 Safari/537.36”,
“饼干”:“SESSDATA=13 bd2abb % 2 c1619949439 % 2 c2815d * b1”, #登录B站后复制一下饼干中的SESSDATA字段,有效期1个月
“主机”:“api.bilibili.com”
}
html=请求。get (url_api header=头). json ()
#打印(html)
#当下载会员视频时,如果饼中传入的不是大会员的SESSDATA时就会返回:{“代码”:-404年,“消息”:“啥都木有”、“ttl”: 1、“数据”:没有}
如果html代码的!=0:
打印(注意!当前集数为B站大会员专享,若想下载,Cookie中请传入大会员的SESSDATA”)
返回“NoVIP”
video_list=[]
因为我在html(“数据”)(“durl”):
video_list.append(我(“url”))
打印(video_list)
返回video_list
#下载视频
“‘
urllib。urlretrieve的回调函数:
def callbackfunc (blocknum blocksize totalsize):
@blocknum:已经下载的数据块
@blocksize:数据块的大小
@totalsize:远程文件的大小
“‘
def Schedule_cmd (blocknum blocksize totalsize):
速度=(blocknum * blocksize)/(time.time () - start_time)
# speed_str="速度:%。2 f %的速度
speed_str="速度:% s " % format_size(速度)
recv_size=blocknum * blocksize
#设置下载进度条
f=sys.stdout
pervent=recv_size/totalsize
percent_str=" %。2 f % % % (pervent * 100)
n=圆(pervent * 50)
s=(“#”* n) .ljust (50,“-”)
f.write (percent_str。“ljust(8日)+ ' (' + s + ') + speed_str)
f.flush ()
# time . sleep (0.1)
f.write ('/r ')
def时间表(blocknum blocksize totalsize):
速度=(blocknum * blocksize)/(time.time () - start_time)
# speed_str="速度:%。2 f %的速度
speed_str="速度:% s " % format_size(速度)
recv_size=blocknum * blocksize
#设置下载进度条
f=sys.stdout
pervent=recv_size/totalsize
percent_str=" %。2 f % % % (pervent * 100)
n=圆(pervent * 50)
s=(“#”* n) .ljust (50,“-”)
打印(percent_str。“ljust (6) +“-”+ speed_str)
f.flush ()
time . sleep (2)
#打印('/r ')
#字节字节转化K/M/G
def format_size(字节数):
试一试:
字节=浮动(字节)
kb=1024字节/除了:
打印(“传入的字节格式不对”)
返回“错误”
如果kb>=1024:
M=kb/1024
如果M>=1024:
G=M/1024
返回“%。3 fg % (G)
其他:
返回“%。3调频“% (M)
其他:
返回“%。3颗“% (kb)
#下载视频
def down_video (start_url video_list、标题,页面):
num=1
打印(“[正在下载第{}话视频,请稍等…]:“.format(页面)+标题)
currentVideoPath=os.path.join (sys。路[0],“bilibili_video”,标题)#当前目录作为下载目录
因为我在video_list:
刀=urllib.request.build_opener ()
#请求头
首场比赛。addheaders=[
#('主机',' upos-hz-mirrorks3.acgvideo.com '), #注意修改主机,不用也行
(“用户代理”、“Mozilla/5.0(麦金塔电脑;Intel Mac OS X 10.13;房车:Firefox 56.0)壁虎/20100101/56.0”),
(“接受”、“*/*”),
(“接收语言”、“en - us, en; q=0.5”),
(接受编码,gzip、缩小、br),
(“范围”、“字节=0 -”),#范围的值要为字节=0,才能下载完整视频
(“推荐人”,start_url), #注意修改推荐人,必须要加的!
(“起源”、“https://www.bilibili.com”),
(“连接”、“维生”),
]
urllib.request.install_opener(刀)
#创建文件夹存放下载的视频
如果不是os.path.exists (currentVideoPath):
os.makedirs (currentVideoPath)
#开始下载
如果len (video_list)> 1:
urllib.request。urlretrieve (url=我,文件名=os.path。加入(currentVideoPath右“{},{}. flv”。格式(标题、num)),
reporthook=Schedule_cmd) #写成mp4也行标题+“-”+ num +“。”
其他:
urllib.request。urlretrieve (url=我,文件名=os.path。加入(currentVideoPath r的{}. flv .format(标题)),
reporthook=Schedule_cmd) #写成mp4也行标题+“-”+ num +“。”
num +=1
#合并视频(20190802新版)
def combine_video (title_list):
video_path=os.path.join (sys。路[0],bilibili_video) #下载目录
title_list的标题:
current_video_path=os.path。加入(video_path、标题)
如果len (os.listdir (current_video_path))>=2:
#视频大于一段才要合并
打印(“[下载完成,正在合并视频…]:' +标题)
#定义一个数组
L=[]
#遍历所有文件
文件的分类(os.listdir (current_video_path),关键=λx: int (x [x.rindex (“-”) + 1: x.rindex (“。”)])):
#如果后缀名为mp4/?
如果os.path.splitext(文件)[1]==啊!?
#拼接成完整路径
filePath=os.path。加入(current_video_path文件)
#载入视频
视频=VideoFileClip (filePath)
#添加到数组
L.append(视频)
#拼接视频
final_clip=concatenate_videoclips(左)
#生成目标视频文件
final_clip.to_videofile (os.path。null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
nullbilibili视频如何利用python进行下载




