听名字就知道这个函数是用来求张量中某个昏暗的前k大或者前k小的值以及对应的指数。
<强>用法
输入:一个张量数据
k:指明是得到前k个数据以及其指数
暗:指定在哪个维度上排序,默认是最后一个维度
最大:如果为真实的,按照大到小排的序,如果为假,按照小到大排序
排序:返回的结果按照顺序返回
:可缺省,不要
topk最常用的场合就是求一个样本被网络认为前k个最可能属于的类别。我们就用这个场景为例,说明函数的使用方法。
假设一个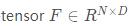 进口火炬
pred=火炬。randn ((4、5))
打印(pred)
值,指数=pred。topk(最大1暗=1=True,排序=True)
打印(指数)
#用最大得到的结果,设置keepdim为真的,避免降维。因为topk函数返回的指数不降维,形状和输入一致。
_,indices_max=pred。max(暗=1,keepdim=True)
打印(indices_max==指数)
# pred
张量([[-0.1480,-0.9819,-0.3364,0.7912,-0.3263),
(-0.8013,-0.9083,0.7973,0.1458,-0.9156),
(-0.2334,-0.0142,-0.5493,0.0673,0.8185),
(-0.4075,-0.1097,0.8193,-0.2352,-0.9273]])
1 #指数、形状为【4】,
张量([[3]#【0 0】代表第一个样本最可能属于第一类别
[2]1 #【0】代表第二个样本最可能属于第二类别
[4],
[2]])
# indices_max等于指数
张量([(真正的),
(真正的),
(真正的),
[事实]])
之前
进口火炬
pred=火炬。randn ((4、5))
打印(pred)
值,指数=pred。topk(最大1暗=1=True,排序=True)
打印(指数)
#用最大得到的结果,设置keepdim为真的,避免降维。因为topk函数返回的指数不降维,形状和输入一致。
_,indices_max=pred。max(暗=1,keepdim=True)
打印(indices_max==指数)
# pred
张量([[-0.1480,-0.9819,-0.3364,0.7912,-0.3263),
(-0.8013,-0.9083,0.7973,0.1458,-0.9156),
(-0.2334,-0.0142,-0.5493,0.0673,0.8185),
(-0.4075,-0.1097,0.8193,-0.2352,-0.9273]])
1 #指数、形状为【4】,
张量([[3]#【0 0】代表第一个样本最可能属于第一类别
[2]1 #【0】代表第二个样本最可能属于第二类别
[4],
[2]])
# indices_max等于指数
张量([(真正的),
(真正的),
(真正的),
[事实]])
之前
<强>现在在尝试一下k=2
可以发现指数的形状变成了【4 k, k=2。
其中指数[0]=[2、3]。其意义是说明第一个样本的前两个最大概率对应的类别分别是第3类和4类第。
大家可以自打印一行下值。可以发现价值观的塑造和指数的形状是一样的.indices描述了在价值观中对应的值在pred中的位置。
以上这篇PyTorch中topk函数的用法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。