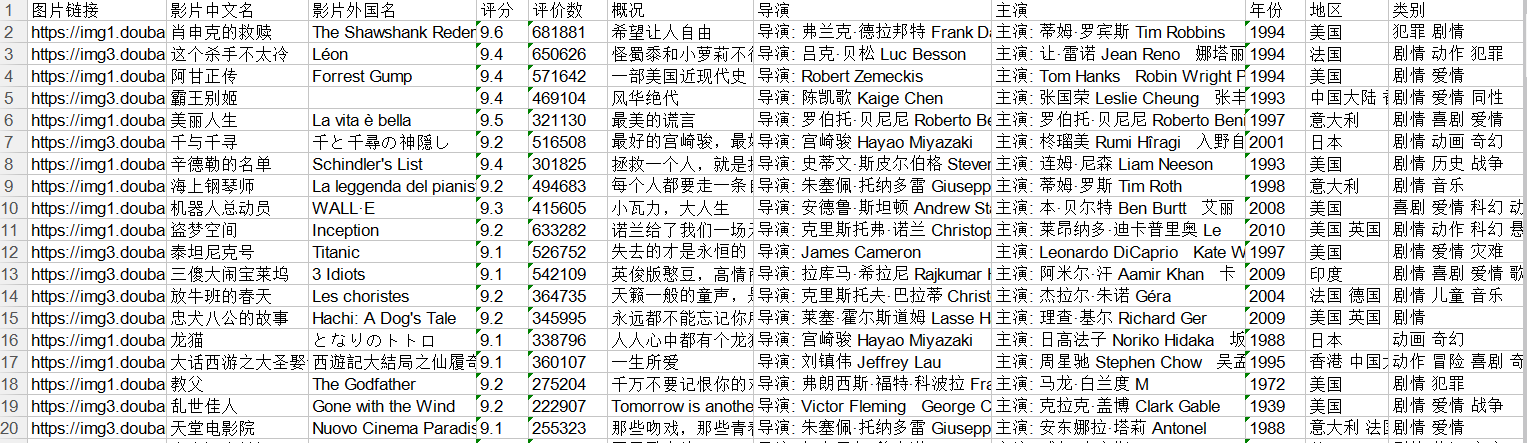
利用python爬取豆瓣电影Top250的相关信息,包括电影详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,导演,主演,年份,地区,类别这12项内容,然后将爬取的信息写入Excel表中。基本上爬取结果还是挺好的,具体代码如下:
# !/usr/bin/python
# - * -编码:utf - 8 - *
导入系统
重载(系统)
sys.setdefaultencoding (use utf8)
从bs4进口BeautifulSoup
进口再保险
进口urllib2
进口xlwt
#得到页面全部内容
def askURL (url):
请求=urllib2.Request (url) #发送请求
试一试:
响应=urllib2.urlopen(请求)#取得响应
html=response.read() #获取网页内容
#打印html
urllib2除外。URLError e:
如果hasattr (e,“代码”):
打印e.code
如果hasattr (e,“原因”):
打印e.reason
返回的html
#获取相关内容
def getData (baseurl):
findLink=re.compile (r & lt; a href=" https://www.yisu.com/zixun/(. * ?)“rel=巴獠縩ofollow”在“)#找到影片详情链接
findImgSrc=https://www.yisu.com/zixun/re.compile (r & lt; img。* src=" https://www.yisu.com/zixun/(。* jpg)”, re.S) #找到影片图片
findTitle=re.compile (r & lt;跨类=氨晏狻弊4?. *)& lt;/span>”) #找到片名
#找到评分
findRating=re.compile (r & lt;跨类=皉ating_num”属性=皏:平均”祝辞(. *)& lt;/span>”)
#找到评价人数
findJudge=re.compile (r & lt; span> (\ d *)人评价& lt;/span>”)
#找到概况
findInq=re.compile (r & lt;跨类=癷nq祝辞(. *)& lt;/span>”)
#找到影片相关内容:导演,主演,年份,地区,类别
findBd=re.compile (r & lt; p class="祝辞(* & # 63;)& lt;/p>”, re.S)
#去掉无关内容
删除=re.compile (r ' | \ n | & lt;/br> | \。*’)
datalist=[]
因为我在范围(0,10):
url=baseurl + str(我* 25)
html=askURL (url)
汤=BeautifulSoup (html、“html.parser”)
项目在soup.find_all (" div " class_=跋钅俊?:#找到每一个影片项
data=https://www.yisu.com/zixun/[]
项=str(项)#转换成字符串
#打印项
链接=re.findall (findLink项)[0]
data.append(链接)#添加详情链接
imgSrc=re.findall (findImgSrc项)[0]
data.append (imgSrc) #添加图片链接
标题=re.findall (findTitle项)
#片名可能只有一个中文名,没有外国名
如果(len(标题)==2):
ctitle[0]=标题
data.append (ctitle) #添加中文片名
otitle=标题[1]。替换("/"," ")#去掉无关符号
data.append (otitle) #添加外国片名
其他:
data.append(标题[0])#添加中文片名
数据。追加(' ')#留空
评级=re.findall (findRating项)[0]
data.append(评级)#添加评分
judgeNum=re.findall (findJudge项)[0]
data.append (judgeNum) #添加评论人数
inq=re.findall (findInq项)
#可能没有概况
如果len (inq) !=0:
inq=inq [0] .replace(“。”, " ") #去掉句号
data.append (inq) #添加概况
其他:
数据。追加(' ')#留空
bd=re.findall (findBd项)[0]
bd=re.sub(删除“bd)
bd=re.sub (“& lt; br>”,“”, bd) #去掉& lt; br>
bd=再保险。子(“/薄ⅰ癰d) #替换/# data.append (bd)
话说=bd。分割(" ")
年代的词:
如果len (s) !=0年代!=' ':#去掉空白内容
data.append (s)
#主演有可能因为导演内容太长而没有
如果(len(数据)!=12):
数据。“插入(8日)#留空
datalist.append(数据)
返回datalist
#将相关数据写入excel中
def saveData (datalist savepath):
书=xlwt.Workbook(编码=皍tf - 8”, style_compression=0)
表=book.add_sheet(“豆瓣电影Top250’, cell_overwrite_ok=True)
坳=(“电影详情链接”,“图片链接”、“影片中文名’,‘影片外国名”,
“评分”、“评价数”,“概况”,“导演”,“主演”、“年份”,“地区”、“类别”)
因为我在范围(0,12):
sheet.write(0,我,[我])上校#列名
因为我在范围(0250):
data=https://www.yisu.com/zixun/datalist[我]
j的范围(0,12):
sheet.write (i + 1, j,数据[j]) #数据
book.save (savepath) #保存
def main ():
baseurl=' https://movie.douban.com/top250& # 63;开始='
datalist=getData (baseurl)
savapath=u '豆瓣电影Top250.xlsx”
saveData (datalist savapath)
main ()
之前
Excel表部分内容如下: