
无论是是自动化登录还是爬的虫,总绕不开验证码,这次就来谈谈python中光学识别验证码模块<代码> tesserocr 和<代码> pytesseract> tesserocr 和<代码> pytesseract> 超正方体> pytesseract> Tesseract-OCR 引擎包装器,所以它们的核心是<代码>超正方体> tesserocr 之前,我们需要先安装<代码>超正方体>
下载地址:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v4.0.0.20181030.exe
下载完成后,双击安装,可以勾选<代码>额外的语言数据(下载)选项来安装OCR识别支持的语言包,但下载语言包实在是慢,我们可以直接从https://github.com/tesseract-ocr/tessdata/下载zip的语言包压缩文件,解压后将<代码> tessdata-master> 超正方体> C: \程序文件(x86) \ Tesseract-OCR \ tessdata 目录下,最后我们配置下环境变量,我们将<代码> C: \程序文件(x86) \ Tesseract-OCR> 超正方体>
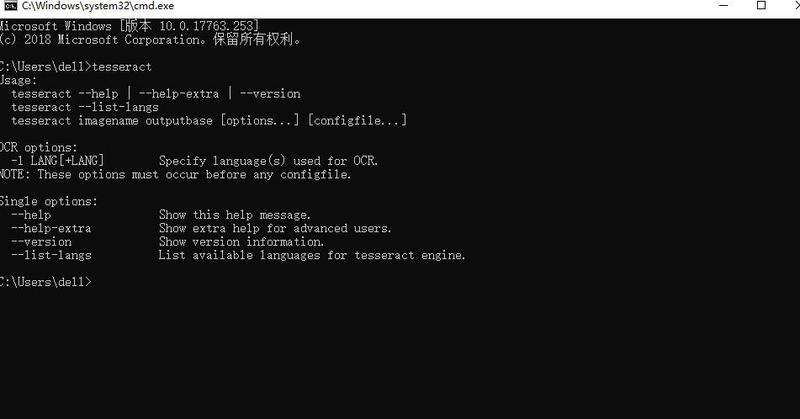
查看安装了的语言包:<代码>超正方体,list-langs
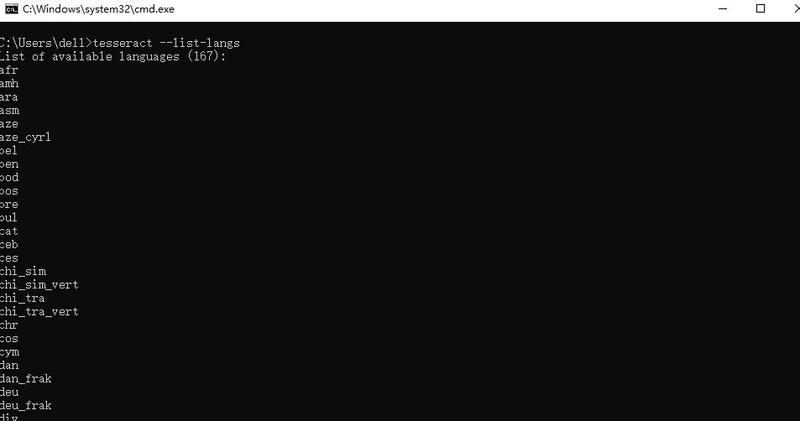
显示我一共安装了167种语言包,里边包含英文或者其他字符。
实验用的二维码
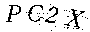
基本使用语法
<代码>超正方体的形象。>
结果

由结果来看,识别出来了p, 2和X,但是把C识别成了G,识别度还是比较高,接下来看在python中的使用
在python下使用pip命令即可完成下载安装<代码> pip安装pytesseract
识别验证码脚本
结果
这样识别的结果同样跟上文一样,个别字符识别的不是很准确
现在网站上的二维码设计的通常很难复杂,如果直接识别的话很难识别出来,下面这段代码是进行灰度处理和二值化
原图

置灰和二值化后

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。




