
周杰伦作为天王,具有划时代的意义毋庸置疑,他的歌伴随了多少个90后的日日夜,夜是多少人的回忆和情怀!

在QQ网页版直接搜索”说好不哭”
很容易就能找到单曲页面
这里是单页评论的获取
所有评论的获取只需递增pagenum即可
返回数据中有很多暂时不需要的字段
这里我们只取其中的用户名,评论时间,评论内容,点赞数
对应如下字段
{,“nick":,“丨那壹刻永遠消失\“\”,,,“praisenum":, 1,“rootcommentcontent":,“越听越好听怎么回事!“,,“time":, 1568729836,}
由于数据量较大这里我们暂时将数据存放在Excel中
一来无须依赖外部数据库
二来可以使用Excel对数据进行二次处理
数据存储代码如下:
def file_do (list_info, file_name):, #,获取文件大小,if not os.path.exists (file_name):, wb =, openpyxl.Workbook (), page =, wb.active page.title =, & # 39;杰# 39;,page.append((& # 39;昵称& # 39;,& # 39;时间& # 39;,& # 39;点赞数& # 39;,& # 39;评论& # 39;]),其他:,wb =, openpyxl.load_workbook (file_name), page =, wb.active for info list_info:拷贝,试题:,page.append(信息),except 例外:,打印(信息),wb.save(文件名=file_name)
首先我们对评论按小时区间进行汇总
由于时间粒度比较小,这里对时间粒度进行了一些处理
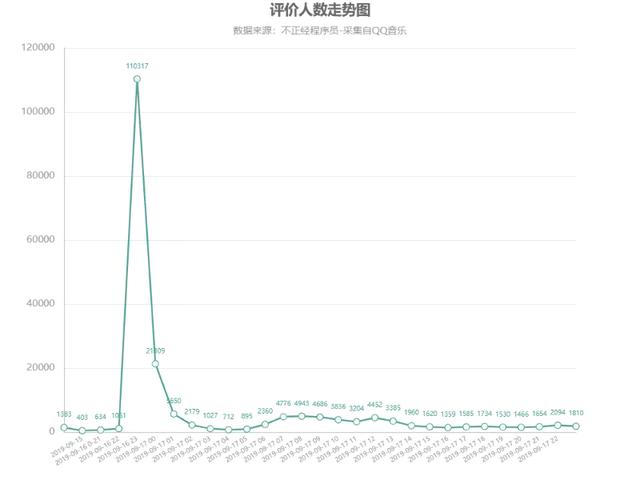 周董新歌《说好不哭》上的线,20 w评论,歌迷都说了些啥
周董新歌《说好不哭》上的线,20 w评论,歌迷都说了些啥




