

绝大部分写业务的程序员,在实际开发中使用复述的时候,只会设置值和获取价值两个操作,对复述整体缺乏一个认知。这里对
如果只是为了分布式锁这些其他功能,还有其他中间件Zookpeer等代替,并非一定要使用复述。
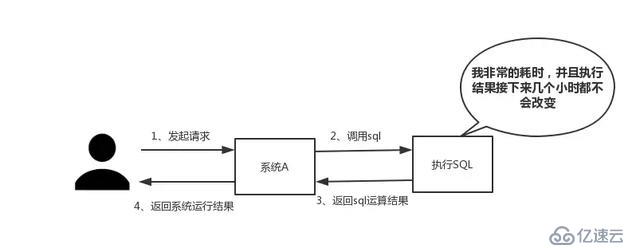
如下图所示,我们在碰到需要执行耗时特别久,且结果不频繁变动的SQL,就特别适合将运行结果放入缓存。这样,后面的请求就去缓存中读取,使得请求能够迅速响应。
根据交互效果的不同,响应时间没有固定标准。在理想状态下,我们的页面跳转需要在瞬间解决,对于页内操作则需要在刹那间解决。
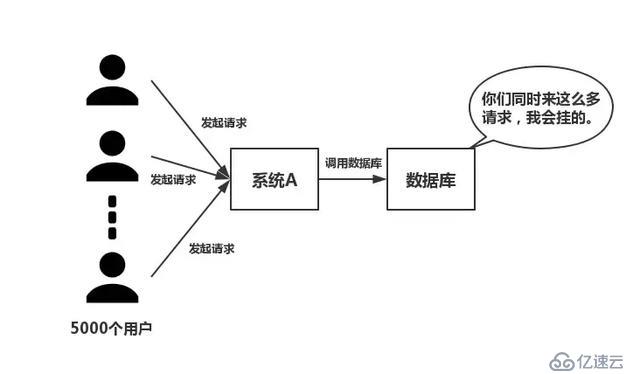
如下图所示,在大并发的情况下,所有的请求直接访问数据库,数据库会出现连接异常。这个时候,就需要使用复述,做一个缓冲操作,让请求先访问到复述,而不是直接访问数据库。
缓存和数据库双写一致性问题
缓存雪崩问题
缓存击穿问题
缓存的并发竞争问题
单线程的 Redis 为什么这么快
这个问题是对 Redis 内部机制的一个考察。很多人都不知道 Redis 是单线程工作模型。
纯内存操作
单线程操作,避免了频繁的上下文切换
采用了非阻塞 I/O 多路复用机制
仔细说一说 I/O 多路复用机制,打一个比方:小曲在 S 城开了一家快递店,负责同城快送服务。小曲因为资金限制,雇佣了一批快递员,然后小曲发现资金不够了,只够买一辆车送快递。
客户每送来一份快递,小曲就让一个快递员盯着,然后快递员开车去送快递。慢慢的小曲就发现了这种经营方式存在下述问题:
时间都花在了抢车上了,大部分快递员都处在闲置状态,抢到车才能去送快递。
随着快递的增多,快递员也越来越多,小曲发现快递店里越来越挤,没办法雇佣新的快递员了。
快递员之间的协调很花时间。
综合上述缺点,小曲痛定思痛,提出了经营方式二。
小曲只雇佣一个快递员。当客户送来快递,小曲按送达地点标注好,依次放在一个地方。最后,让快递员依次去取快递,一次拿一个,再开着车去送快递,送好了就回来拿下一个快递。上述两种经营方式对比,很明显第二种效率更高。
每个快递员→每个线程
每个快递→每个 Socket(I/O 流)
快递的送达地点→Socket 的不同状态
客户送快递请求→来自客户端的请求
小曲的经营方式→服务端运行的代码
一辆车→CPU 的核数
经营方式一就是传统的并发模型,每个 I/O 流(快递)都有一个新的线程(快递员)管理。
经营方式二就是 I/O 多路复用。只有单个线程(一个快递员),通过跟踪每个 I/O 流的状态(每个快递的送达地点),来管理多个 I/O 流。




