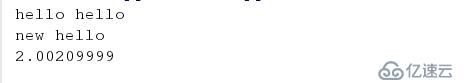模块
1。模块介绍
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式,在Python中,一个. py文件就称之为一个模块。
2。使用模块的好处:
最大的好处是大大提高了代码的可维护性。其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。点这里查看Python的所有内置函数。
3。模块分类
模块分为三种:
(1)自定义模块
(2)内置标准模块(又称标准库)
(3)。开源模块
4。模块导入
(1)进口xxx
直接导入模块。
导入时执行的动作:
产生一个新的名称空间;
在新建的名称空间里面执行模块(. py)的内容,
拿到模块名,执行模块文件产生的名称空间。
(2)进口xxx和yyy
导入模块并重新赋予一个名字(不会改变模块本身的名字)
(3)从…进口xxx
从一个模块里导入函数,变量,装饰器等……
从…进口
将某个模块的所有内容导入。代表所有。
用这种格式导入的时候iu,可以在模块中添加代码:
<代码> __all__=[这里写允许从这个模块导入的内容)
例如:
<代码>导入时间 一个=100 def运行时(有趣的): def包装(): start_time=time.time () 有趣的() end_time=time.time () 打印(“%。8 f ' % (end_time-start_time)) 返回包装 def hello (): 打印(“你好你好”) 从xxx # __all__用来控制进口*导入的内容,此处表示只允许导入装饰器rumTime和变量,而方法你好则不会被导入。 __all__=[“运行时”,“一”) 你好()
从…进口xxx和yyy
导入内容并重新命名。
5。常用内置模块
1.时间模块https://www.cnblogs.com/tkqasn/p/6001134.html
2.随机模块https://blog.csdn.net/zheng_lan_fang/article/details/76684761
3.数学模块https://blog.csdn.net/qq_38092017/article/details/76216137
4.串模块https://blog.csdn.net/github_36601823/article/details/77815013
5.操作系统模块https://www.cnblogs.com/ginvip/p/6439679.html
6.系统模块https://baijiahao.baidu.com/s?id=1594972087849221139&wfr=spider&for=pc
6。模块导入时查找顺序
在导入模块时,模块在python中的查找顺序为:
<代码>内存中已经加载的模块,祝辞内置模块,祝辞sys.path目录里面的模块
-
<李>内存中已经加载的模块:pythonj解释器在启动时默认自动加载的模块,可以通过sys.modules查看,sys.modules是一个字典,由模块名和模块信息构成键值对。
<李> sys.path记录了导入模块的搜索路径,按照路径的先后顺序去搜索。
<强>注意:强自定义模块时,模块名字不要和内置模块冲突,否则导入的是自定义模块,无法导入系统内置模块。
7。解决问题
1。在导入模块时,模块中的执行结果会和当前py文件中执行结果一起显示。
例如:
有一个myRunTime模块如下:
<代码>导入时间 一个=100 def运行时(有趣的): def包装(): start_time=time.time () 有趣的() end_time=time.time () 打印(“%。8 f ' % (end_time-start_time)) 返回包装 def hello (): 打印(“你好你好”) 你好()
将模块导入:
<代码>导入时间 进口myRunTime @myRunTime.runTime def new_hello (): time . sleep (2) 打印(“新你好”) new_hello()
运行会发现,模块中的内容也显示了出来。