本篇内容主要讲解“Python怎么实现爬取腾讯招聘网岗位信息”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Python怎么实现爬取腾讯招聘网岗位信息”吧!
介绍
开发环境
Windows 10
python3.6
开发工具
pycharm
库
numpy、matplotlib、time、xlutils.copy、os、xlwt, xlrd, random
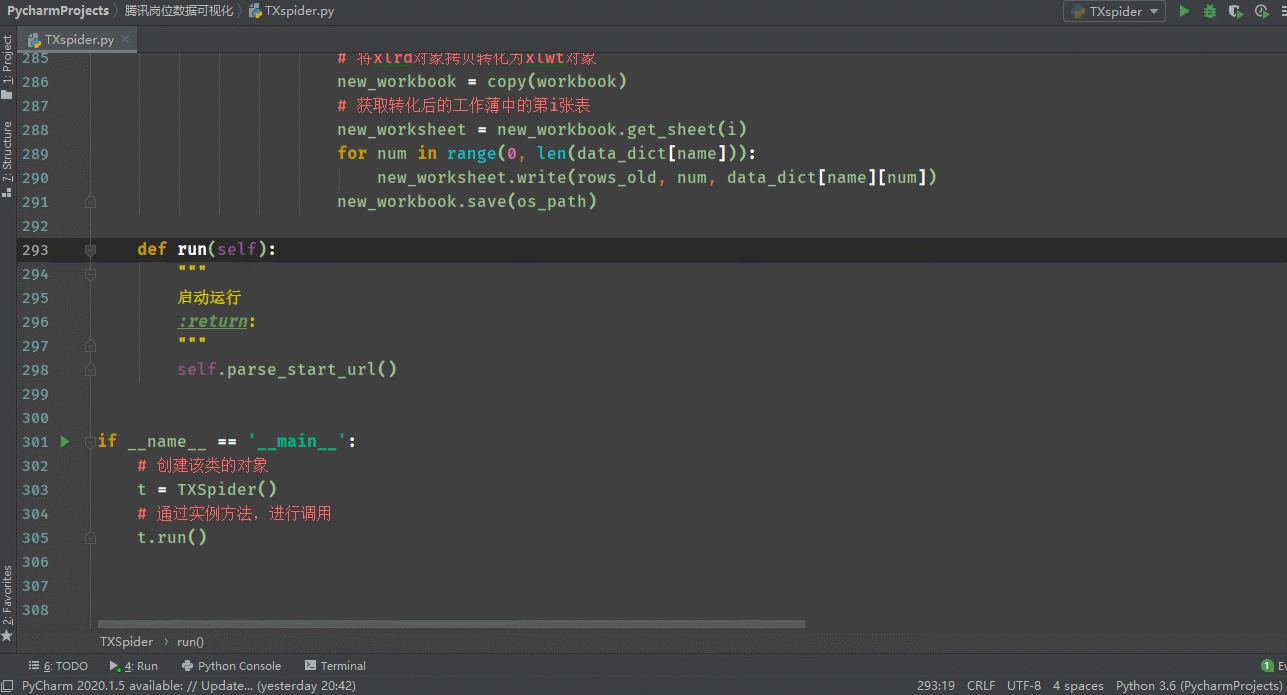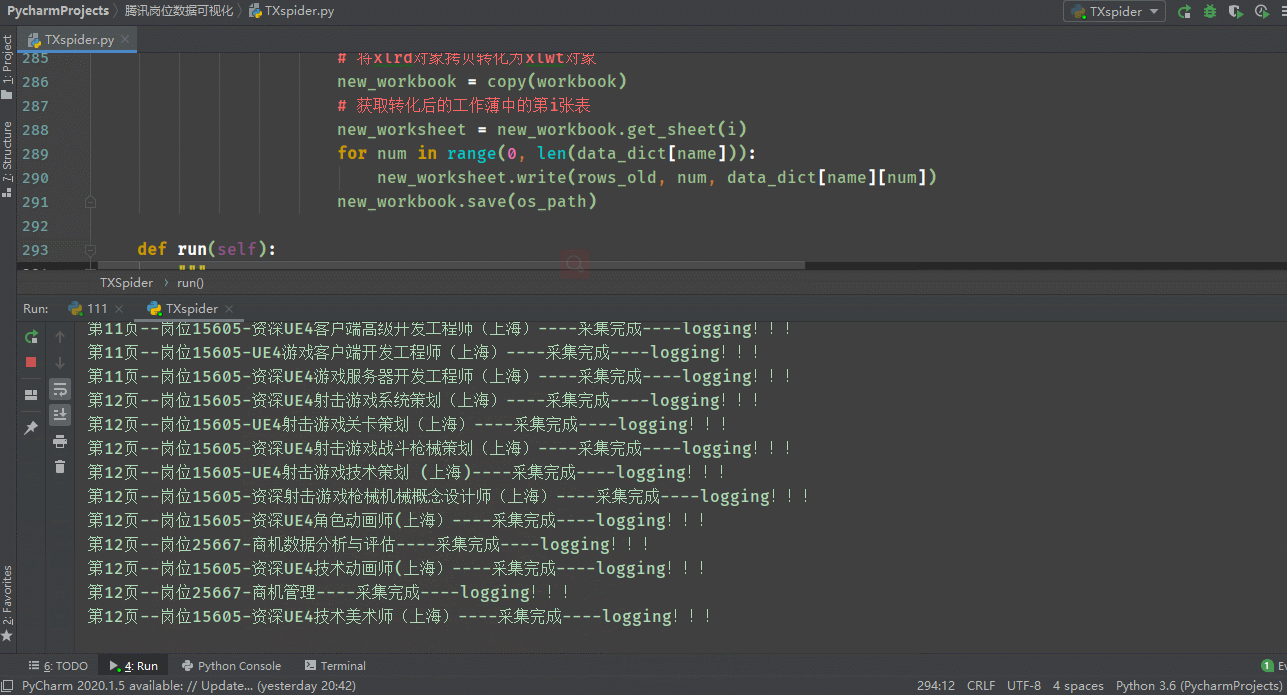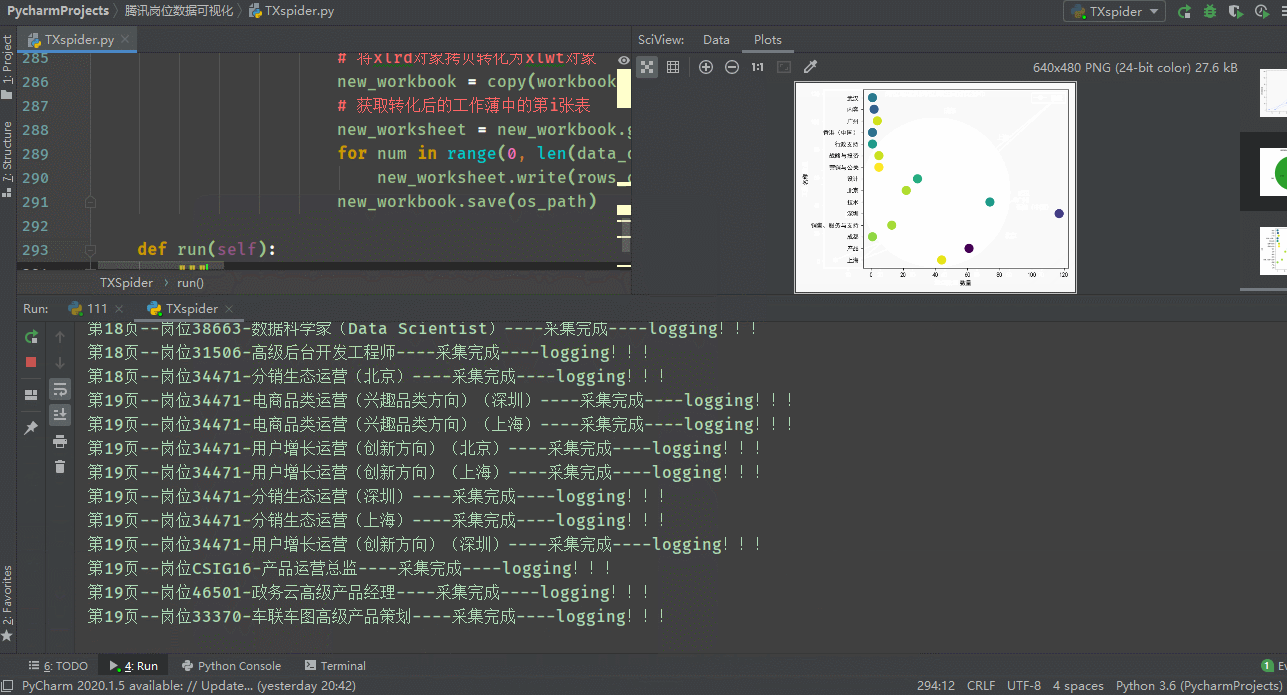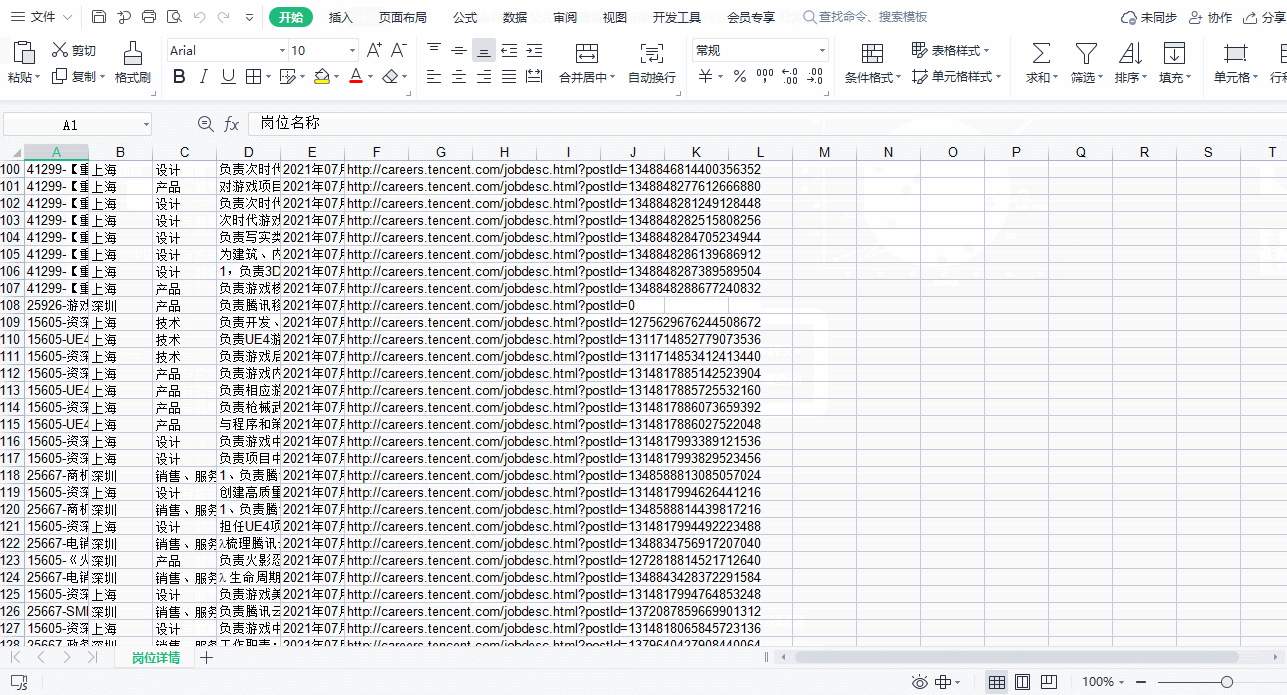
效果展示
代码运行展示

实现思路
1.打开腾讯招聘的网址右击检查进行抓包,进入网址的时候发现有异步渲染,我们要的数据为异步加载
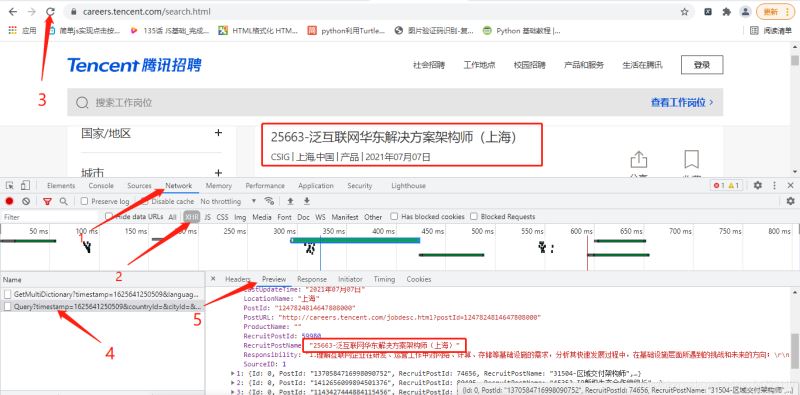
2.构造起始地址:
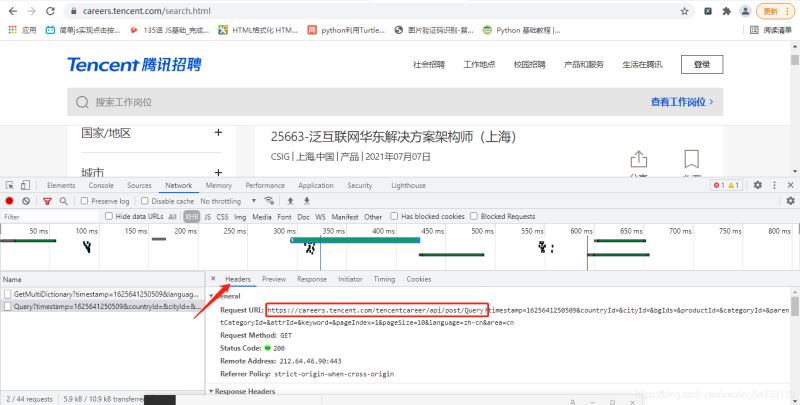
start_url = ‘https://careers.tencent.com/tencentcareer/api/post/Query’
参数在headers的最下面
timestamp: 1625641250509
countryId:
cityId:
bgIds:
productId:
categoryId:
parentCategoryId:
attrId:
keyword:
pageIndex: 1
pageSize: 10
language: zh-cn
area: cn
3.发送请求,获取响应
self.start_url = 'https://careers.tencent.com/tencentcareer/api/post/Query'
# 构造请求参数
params = {
# 捕捉当前时间戳
'timestamp': str(int(time.time() * 1000)),
'countryId': '',
'cityId': '',
'bgIds': '',
'productId': '',
'categoryId': '',
'parentCategoryId': '',
'attrId': '',
'keyword': '',
'pageIndex': str(self.start_page),
'pageSize': '10',
'language': 'zh-cn',
'area': 'cn'
}
headers = {
'user-agent': random.choice(USER_AGENT_LIST)
}
response = session.get(url=self.start_url, headers=headers, params=params).json()4.提取数据,获取岗位信息大列表,提取相应的数据
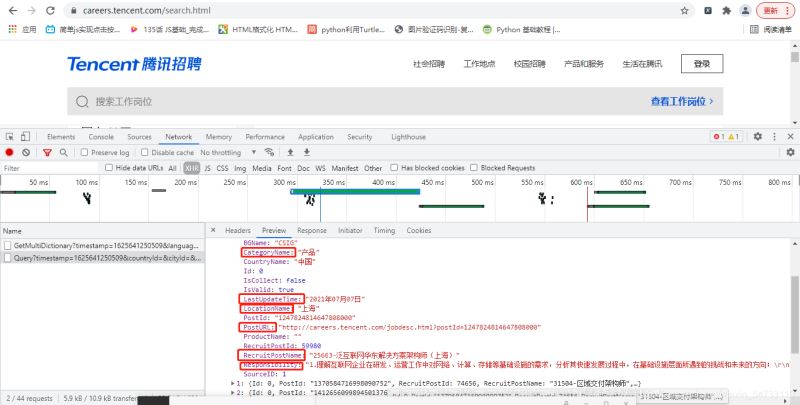
# 获取岗位信息大列表 json_data = response['Data']['Posts'] # 判断结果是否有数据 if json_data is None: # 没有数据,设置循环条件为False self.is_running = False # 反之,开始提取数据 else: # 循环遍历,取出列表中的每一个岗位字典 # 通过key取value值的方法进行采集数据 for data in json_data: # 工作地点 LocationName = data['LocationName'] # 往地址大列表中添加数据 self.addr_list.append(LocationName) # 工作属性 CategoryName = data['CategoryName'] # 往工作属性大列表中添加数据 self.category_list.append(CategoryName) # 岗位名称 RecruitPostName = data['RecruitPostName'] # 岗位职责 Responsibility = data['Responsibility'] # 发布时间 LastUpdateTime = data['LastUpdateTime'] # 岗位地址 PostURL = data['PostURL']Python怎么实现爬取腾讯招聘网岗位信息