介绍
这篇文章主要介绍Python3如何实现邮政分卷压缩,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
Python的优点有哪些 1,简单易用,与C/c++、Java、c#等传统语言相比,Python对代码格式的要求没有那么严格;2,Python属于开源的,所有人都可以看到源代码,并且可以被移植在许多平台上使用;3,Python面向对象,能够支持面向过程编程,也支持面向对象编程;4,Python是一种解释性语言,Python写的程序不需要编译成二进制代码,可以直接从源代码运行程序;5,Python功能强大,拥有的模块众多,基本能够实现所有的常见功能。
<强>使用zipfile库
利用Python压缩zip文件,我们第一反应是使用zipfile库,然而,它的官方文档中却明确标注“此模块目前不能处理分卷压缩文件”
<强>折腾经过
翻遍了谷歌,CSDN, Stackoverflow等平台均未找到解决方案,最靠谱的是调用外部解压程序实现分卷压缩的功能。但是,如何不依靠外部程序实现这个功能呢? ?
于是乎,只能自己慢慢造轮子。看着邮政格式开发商留下的文档zip文件格式规范,头疼啊(;及;急性;д”)。于是我拿着WinHex开始16进制一个一个文件对比解压缩的软件创建的分卷压缩和单个邮政文件的差异。
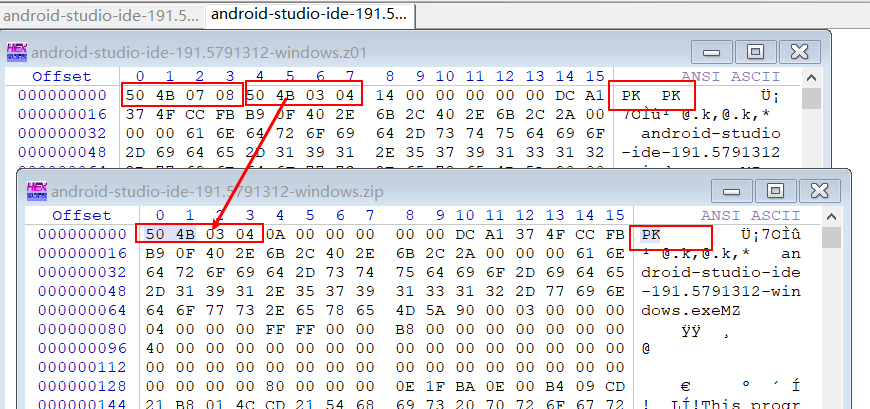
如果想把单个大文件测试。zip→分卷文件test.z01 test.z02,测试。zip
首先,在创建的第一个分卷文件测试。z01的前面加上\×50 \ x4b \ x07 \(这个是分卷压缩的文件头(头),占4个字节。其实单个压缩文件本身头就有这个了,而分卷压缩的需要两个emmm。之后便是从单个大压缩文件文件测试。zip中读取“一个分卷大小4个字节“的数据,写入test.z01中,如何接着读取一个分卷大小的数据,写入test.z02,以此类推,最后一个分卷文件名也是测试。zip .
<>强Python3的代码实现
import 操作系统
import zipfile
def zip_by_volume (file_path, block_size):
“““才能zip文件分卷压缩“““
时间=file_size 才能;os.path.getsize (file_path), #,文件字节数
路径,才能,file_name =, os.path.split (file_path), #,除去文件名以外的道路,文件名
时间=suffix 才能;file_name.split(& # 39; # 39;公司)[1],#,文件后缀名
#,才能添加到临时压缩文件
zip_file 才能=,file_path +, & # 39; . zip # 39;
with 才能;zipfile.ZipFile (zip_file, & # 39; w # 39;), as zf:
,,,zf.write (file_path, arcname=file_name)
#才能,小于分卷尺寸则直接返回压缩文件路径
if 才能file_size & lt;=, block_size:
,,,return zip_file
其他的才能:
,,,fp =,开放(zip_file, & # 39; rb # 39;)
,,,count =, file_size //, block_size + 1
,,,#,创建分卷压缩文件的保存路径
,,,save_dir =, path +, os.sep +, file_name +, & # 39; _split& # 39;
,,,if os.path.exists (save_dir):
,,,,,得到shutil import rmtree
,,,,,rmtree (save_dir)
,,,os.mkdir (save_dir)
,,,#,拆分压缩包为分卷文件
,,,for 小姐:拷贝范围(1,count +, 1):
,,,,,_suffix =, & # 39; z{: 0比2}& # 39;.format (i), if 小姐:!=,count else & # 39;邮政# 39;
,,,,,name =, save_dir +, os.sep +, file_name.replace (str(后缀),_suffix)
,,,,,f =,开放(名字,,& # 39;wb + & # 39;)
,,,,,if 小姐:==,1:
,,,,,,,f.write (b # 39; \×50 \ x4b \ x07 \(# 39;), #,添加分卷压缩头(4字节)
,,,,,,,f.write (fp.read (block_size 作用;4))
,,,,,其他的:
,,,,,,,f.write (fp.read (block_size))
,,,fp.close ()
,,,os.remove (zip_file),,, #,删除临时的,zip 文件,,
,,,return save_dir
if __name__ ==, & # 39; __main__ # 39;:
时间=file 才能;r" D: \下载\ 1. mp4",,,, #,原始文件
volume_size 才能=,1024,*,1024,*,100,#,分卷大小,100 mb
时间=path 才能;zip_by_volume(文件,,volume_size)
打印才能(路径),,,#,输出分卷压缩文件的路径 <强>缺点
该方法创建分卷压缩的时候,需要先在磁盘创建一个临时压缩包,然后将其拆分,实际上会对磁盘写入两次,这就浪费了时间。
当然,我尝试使用ByteIO进行字节流的压缩,但是这种方式需要先把文件读入内存,对于超级大的文件,这是不现实的,分分钟内存爆炸。





