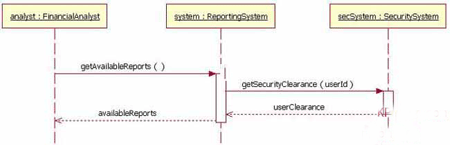
怎么在python中使用结构体模块对字节型数据进行处理?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
<强>字节顺序
一个数据有多个字节表示的时候,字节的顺序不同也就决定了值,在结构中有以下几种字节顺序:
字符字节顺序尺寸对齐方式@本机本机本机=本机标准无& lt;小端标准无祝辞大端标准无!网络标准无对于字节顺序,只有大端和小端两种方式,只是比如你用@和=代表你用本机的字节顺序,!代表你使用网络的字节顺序。你不指定字节顺序则默认的是@。
本地字节顺序是大端或小端,取决于主机系统,例如,英特尔x86和AMD64 (x86 - 64)是小端的;68000年摩托罗拉和PowerPC G5是大端;手臂和英特尔安腾具有可切换的字节序(双字节序)。使用系统。byteorder来检查你的系统的字节顺序。
<强>数据格式
struct支持的打包解包的数据格式如下,我们需要指定格式才能对应处理,其中对应尺寸已列出(以字节为单位):
字符C类型python类型标准尺寸x填充字节没有意义的值cchar长度为1的字节1 bsigned char整型1 bunsigned char整型1 ? _Bool布尔1 hshort整型2 hunsigned短整型2 iint整型4 iunsigned int整型4 llong整型4 lunsigned长整型4 qlong长整型长8 qunsigned长整型8 nssize_t整型
Nsize_t整型e
浮动2 ffloat浮动4 ddouble浮动8 schar[]字节
pchar[]字节
Pvoid *整型
<>强打包
通过结构的包(fmt, * args)来实现对各种数据的打包(转换为对应字节数据),包的需要传递的参数fmt就是数据的格式,包括了字节顺序,数据类型;后面的* args参数是需要打包的数据。
vaa=struct.pack(& # 39;在我# 39;,1255)# vaa: & # 39; \ x00 \ x00 \ x04 \ xe7& # 39;1 * 4=1个字节还有vab=struct.pack(& # 39;在2 # 39;,1255,23)#还有vab: & # 39; \ x00 \ x00 \ x04 \ xe7 \ x00 \ x00 \ x00 \ x17 # 39;2 * 4=8个字节休假=struct.pack(& # 39;在2我? & # 39;,1255年,23岁,真的)#真空吸尘器:& # 39;\ x00 \ x00 \ x04 \ xe7 \ x00 \ x00 \ x00 \ x17 \ x01 # 39;2 * 4 + 1=9个字节
我们看上述三个使用例子(数据与数据之间没有填充,都是连续的,比如对于休假我们不知道它是由两个四字节无符号整型和一个布尔构成,我们就无法取得正确的值),看fmt参数:
的祝辞我# 39;代表了以大端的字节顺序打包一个4字节无符号整型数据,所以后面只跟了一个无符号整型参数1255;
'在2 # 39;代表了以大端的字节顺序打包两个4字节无符号整型数据,所以后面跟了两个个无符号整型参数1255和23;
'在2我? & # 39;代表了以大端的字节顺序打包两个4字节无符号整型和一个布尔型数据,所以后面跟了两个个无符号整型参数1255年,23岁和一个布尔值True。
注意& # 39;2我# 39;和& # 39;2 # 39;,& # 39;4我# 39;和& # 39;IIII& # 39;, & # 39; 2 ? & # 39;和& # 39;? ? & # 39;是一样的效果。
<>强解包
通过结构的解压缩(fmt,字符串)来实现对字符串的解包,fmt和打包的是完全一样的,如下(返回的结果是一个元组):
<强>进阶使用
pack_into (fmt,缓冲区,抵消,* args)
fmt参数和包装是一样的,缓冲参数是可写的缓存区,抵消是写入位置的偏移量,* args是需要写入的数据。这个有什么用呢,我们想想这样两个情况,我们有两个类型已经打包好,我们想在这两个已经打包好的数据后面再添加一个数据打包,或者我们要打包的数据很多,我们不可能在包中把所有需要打包的数据都通过参数传递给包,那你的包函数可能得写成千上完个参数了。这时候我们就可以用到这个函数了。
要使用它必须要一个可以写入的缓存区,我们可以导入一个字符缓存区包,然后创建一个固定大小的缓存区(以字节为单位):