今天就跟大家聊聊有关Python中关联的规则有哪些,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
1。关联规则
大家可能听说过用于宣传数据挖掘的一个案例:啤酒和尿布;据说是沃尔玛超市在分析顾客的购买记录时,发现许多客户购买啤酒的同时也会购买婴儿尿布,于是超市调整了啤酒和尿布的货架摆放,让这两个品类摆放在一起;结果这两个品类的销量都有明显的增长;分析原因是很多刚生小孩的男士在购买的啤酒时,会顺手带一些婴幼儿用品。
不论这个案例是否是真实的,案例中分析顾客购买记录的方式就是关联规则分析法Association Rules。
关联规则分析也被称为购物篮分析,用于分析数据集各项之间的关联关系。
1.1 基本概念
项集:item的集合,如集合{牛奶、麦片、糖}是一个3项集,可以认为是购买记录里物品的集合。
频繁项集:顾名思义就是频繁出现的item项的集合。如何定义频繁呢?用比例来判定,关联规则中采用支持度和置信度两个概念来计算比例值
支持度:共同出现的项在整体项中的比例。以购买记录为例子,购买记录100条,如果商品A和B同时出现50条购买记录(即同时购买A和B的记录有50),那边A和B这个2项集的支持度为50%
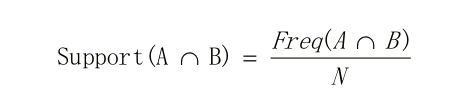
置信度:购买A后再购买B的条件概率,根据贝叶斯公式,可如下表示:
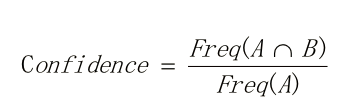
提升度:为了判断产生规则的实际价值,即使用规则后商品出现的次数是否高于商品单独出现的评率,提升度和衡量购买X对购买Y的概率的提升作用。如下公式可见,如果X和Y相互独立那么提升度为1,提升度越大,说明X->Y的关联性越强

1.2 关联规则Apriori算法
关联规则方法的步骤如下:
发现频繁项集
找出关联规则
Apriori算法是经典的关联规则算法。Apriori算法的目标是找到最大的K项频繁集。Apriori算法从寻找1项集开始,通过最小支持度阈值进行剪枝,依次寻找2项集,3项集直到没有更过项集为止。
下面是一个案例图解:
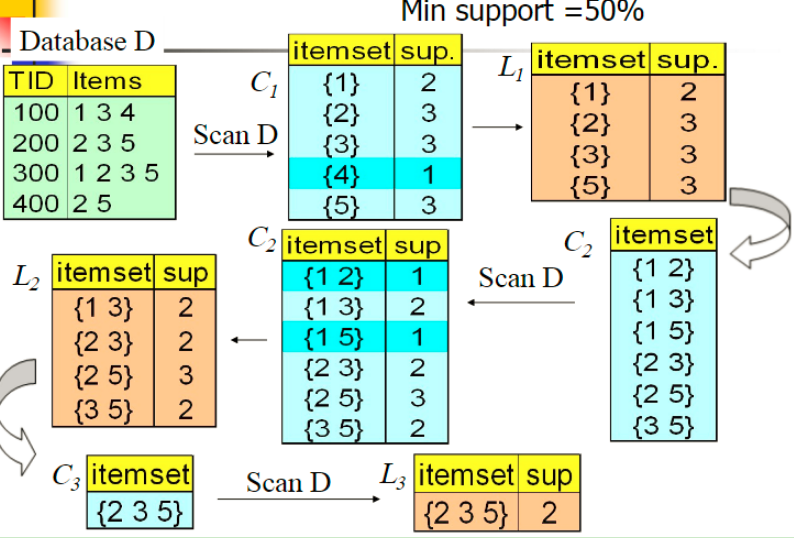
图中有4个记录,记录项有1,2,3,4,5若干
首先先找出1项集对应的支持度(C1),可以看出4的支持度低于最小支持阈值,先剪掉(L1)。
从1项集生成2项集,并计算支持度(C2),可以看出(1,5)(1,2)支持度低于最小支持阈值,先剪掉(L2)
从2项集生成3项集,(1,2,3)(1,2,5)(2,3,5)只有(2,3,5)满足要求
没有更多的项集了,就定制迭代
2. mlxtend实战关联规则
关联规则目前在scikit-learn中并没有实现。这里介绍另一个python库mlxtend .
2.1安装
2.2简单的例子
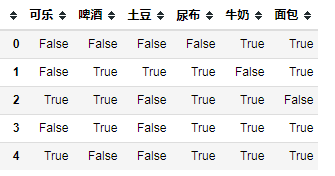
来看下数据集:
数据格式处理,传入模型的数据需要满足bool值的格式