这篇文章主要介绍”如何将MongoDB作为循环队列”,在日常操作中,相信很多人在如何将MongoDB作为循环队列问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答“如何将MongoDB作为循环队列”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
我们在使用MongoDB的时候,一个集合里面能放多少数据,一般取决于硬盘大小,只要硬盘足够大,那么我们可以无休止地往里面添加数据。
然后,有些时候,我只想把MongoDB作为一个循环队列来使用,期望它有这样一个行为:
设定队列的长度为10
<李>插入第1条数据,它被放在第1个位置
<李>插入第2条数据,它被放在第2个位置
<李>…
<李>插入第十条数据,它被放在第十个位置
<李>插入第11条数据,它被放在第1个位置,覆盖原来的内容
<李>插入第12条数据,它被放在第2个位置,覆盖原来的内容
<李>…
MongoDB有一种叫集合做了收集,就是为了实现这个目的而设计的。
普通的集合不需要提前创建,只要往MongoDB里面插入数据,MongoDB自动就会创建。而限制收集需要提前定义一个集合为限制类型。
语法如下:
对一个数据库对象使用create_collection方法,创建集合,其中参数上限=True说明这是一个限制收集,并限定它的大小为10 mb,这里的大小参数的单位是字节,所以10 mb就是1024 * 1024 * 10。max=5表示这个集合最多只有5条数据,一旦超过5条,就会从头开始覆盖。
创建好以后,将收集的插入操作和查询操作就和普通的集合完全一样了:
这里我插入了5条数据,效果如下图所示:
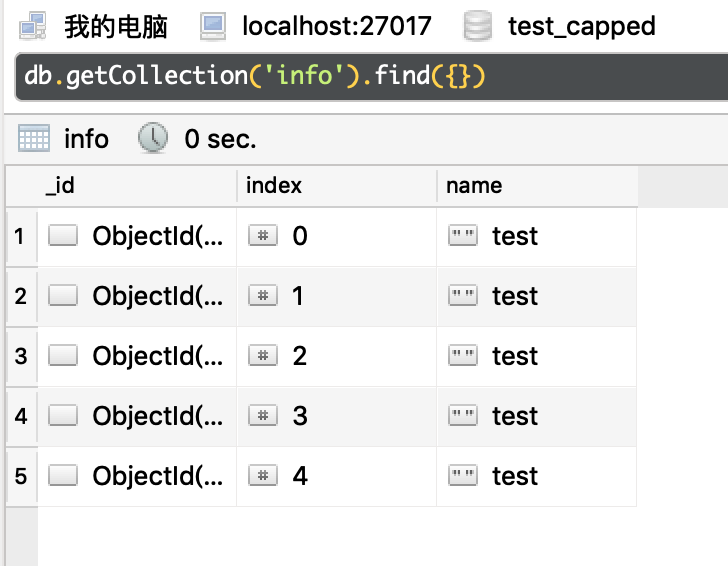
其中,索引为0的这一条是最先插入的。
接下来,我再插入一条数据:
此时数据库如下图所示:
可以看的到,索引为0的数据已经被最新的数据覆盖了。
我们再插入一条数据看看:
运行效果如下图所示:
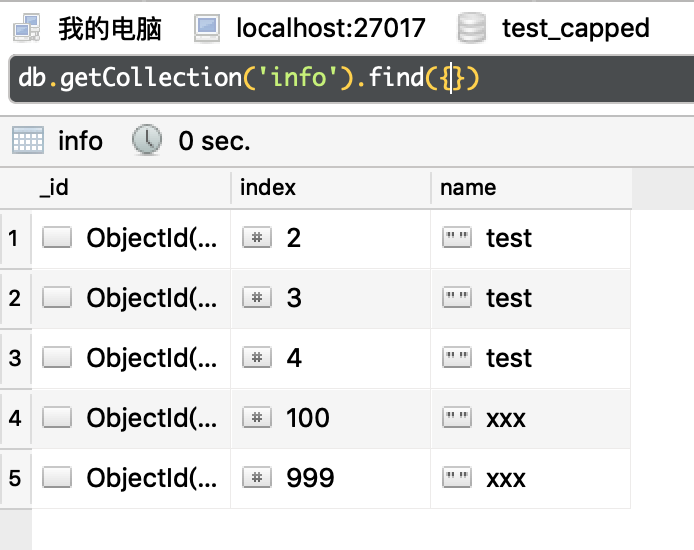
可以看的到,指数为1的数据也被覆盖了。
这样我们就实现了一个循环队列。
MongoDB对限制收集有特别的优化,所以它的读写速度比普通的集合快。
但是限制集合也有一些缺点,在MongoDB的官方文档中提到:
如果更新或替换操作改变文件大小,操作将会失败。
你不能删除文件从一个集合。从一个集合,删除所有文件使用滴水()方法来收集和重新创建集合。
意思就是说,限制集合里面的每一条记录,可以更新,但是更新不能改变记录的大小,否则更新就会失败。
不能单独删除限制集合中任何一条记录,只能整体删除整个集合然后重建。
总结
到此,关于“如何将MongoDB作为循环队列”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注网站,小编会继续努力为大家带来更多实用的文章!
如何将MongoDB作为循环队列