
<强>再保险模块
再保险模块使Python语言拥有全部的正则表达式功能。
编译函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
<强>转义符
正则表达式中用“\”表示转义,而python中也用“\”表示转义,当遇到特殊字符需要转义时,你要花费心思到底需要几个“\”,所以为了避免这个情况,推荐使用原生字符串类型(原始字符串)来书写正则表达式。
方法很简单,只需要在表达式前面加个“r”即可,如下:
<代码> r ' \ d {2} - \ d {8} '
r \ bt \ w * \ b的
<强>常用函数

<强> re.match()
从字符串的起始位置匹配,匹配成功,返回一个匹配的对象,否则返回没有
<代码>语法:再保险。匹配(模式、字符串、旗帜=0) 模式:匹配的正则表达式 字符串:要匹配的字符串 国旗:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等;旗帜=0表示不进行特殊指定
可选标志如下:
修饰符被指定为一个可选的标志。多个标志可以通过按位或(|)它们来指定。如re.I | re.M被设置成我和M标志

<强> re.search()
扫描整个字符串并返回第一个成功的匹配对象,否则返回没有
语法:再保险。搜索(模式、字符串、旗帜=0)
<强> re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回没有;而re.search匹配整个字符串,直到找到一个匹配(注意:仅仅是第一个)
<强> re.findall()
在字符串中找到正则表达式所匹配的所有子串,并返回一个列的表,如果没有找到匹配的,则返回空列表
注意:匹配和搜索是匹配一次,而findall匹配所有
<强> re.split()
根据正则表达式中的分隔符把字符分割为一个列表并返回成功匹配的列表。
<强> re.sub()
用于替换字符串中的匹配项
语法:re.sub(模式,repl,字符串,count=0)
<代码>模式:正则中的模式字符串。 repl:替换的字符串,也可为一个函数。 字符串:要被查找替换的原始字符串。 数:模式匹配后替换的最大次数,默认0表示替换所有的匹配。
<强> re.compile()
编译函数用于编译正则表达式,生成一个正则表达式(模式)对象,然后就可以用编译后的正则表达式去匹配字符串
<代码>模式:一个字符串形式的正则表达式 国旗:可选,表示匹配模式,比如忽略大小写,多行模式等
<强>贪婪匹配和非贪婪匹配
贪婪匹配:匹配尽可能多的字符;非贪婪匹配:匹配尽可能少的字符
python的正则匹配默认是贪婪匹配
, <代码>祝辞的在比;re.match (r ' ^ (\ w +) (\ d *)美元”,“abc123”) .groups ()
(“abc123”、”)
在在在re.match (r ^ (\ w + ?) (\ d *)美元”,“abc123”) .groups ()
(' abc ', ' 123 ')
表达式1:
\ w +表示匹配字母或数字或下划线或汉字并重复1次或更多次;\ d *表示匹配数字并重复0次或更多次。
分1组中(\ w)是贪婪匹配,它会在满足分2组(\ d *)的情况下匹配尽可能多的字符,
因为分组2 (\ d *)匹配0个数字也满足,所以分1组就把所有字符全部匹配掉了,分组2只能匹配空了。
表达式2:在表达式后加个?即可进行非贪婪匹配,如上面的(\ w + ?)
因为分1组进行非贪婪匹配,也就是满足分组2匹配的情况下,分1组尽可能少的匹配,
这样的话,上面分2组(\ d *)会把所有数字(123)都匹配,所以分组1匹配到(abc)
<强>常见匹配模式
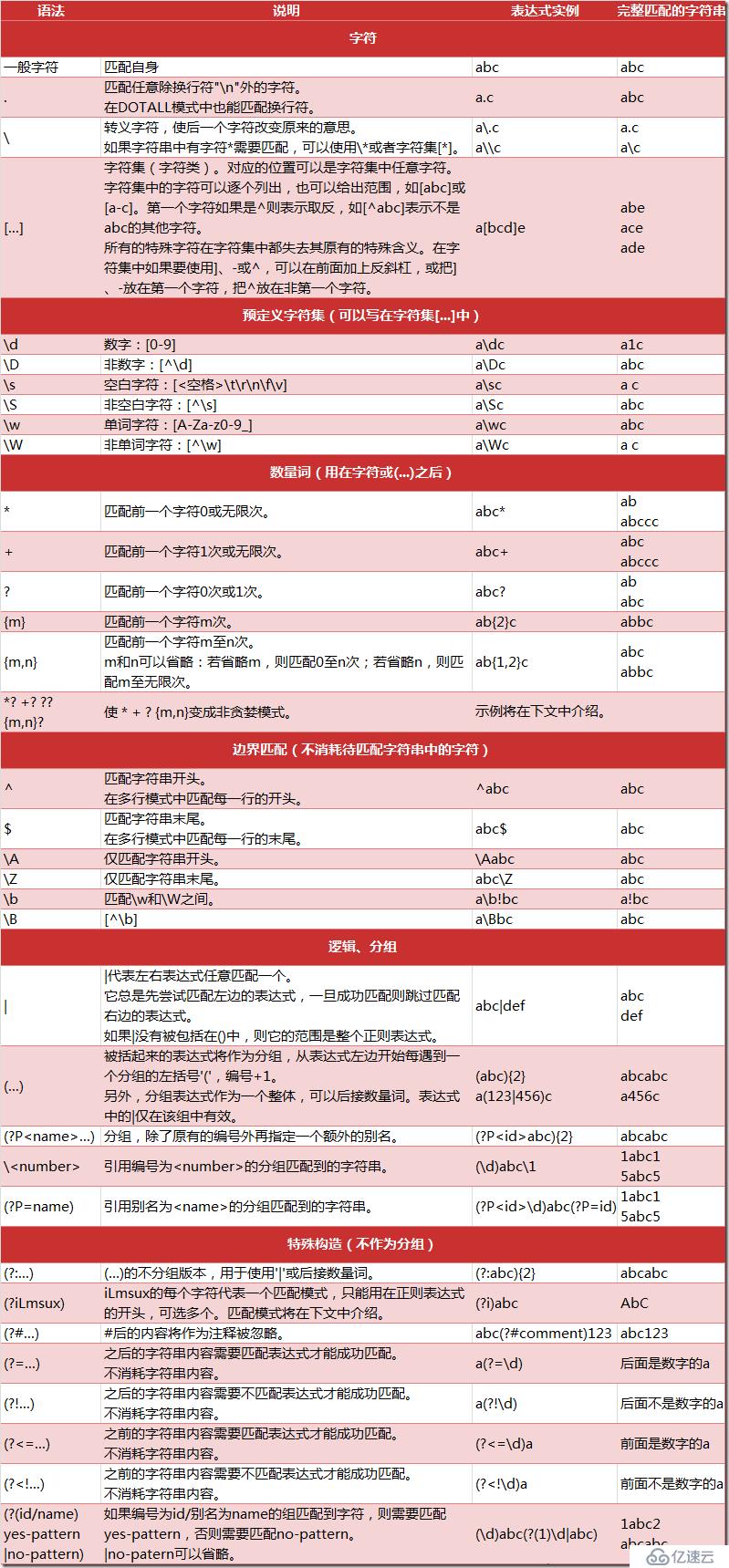
<代码>正则式需要匹配不定长的字符串,那就一定需要表示重复的指示符.Python的正则式表示重复的功能很丰富灵活。重复规则的一般的形式是在一条字符规则后面紧跟一个表示重复次数的规则,已表明需要重复前面的规则一定的次数。python爬取准备二正则表达式




