本篇内容介绍了“怎么在SAP HANA Express Edition里进行文本分析”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
这个练习会使用SAP HANA Express Edition的文本语义分析引擎对JSON格式的文件进行语义分析。
首先创建一个表列,对其指数开启模糊文本搜索(模糊搜索)功能。
上述描述的操作可以用下面的SQL语句来完成:
创建列表food_analysis
(
名称nvarchar (64),
描述文本快速预处理alt="怎么在SAP HANA Express Edition里进行文本分析">
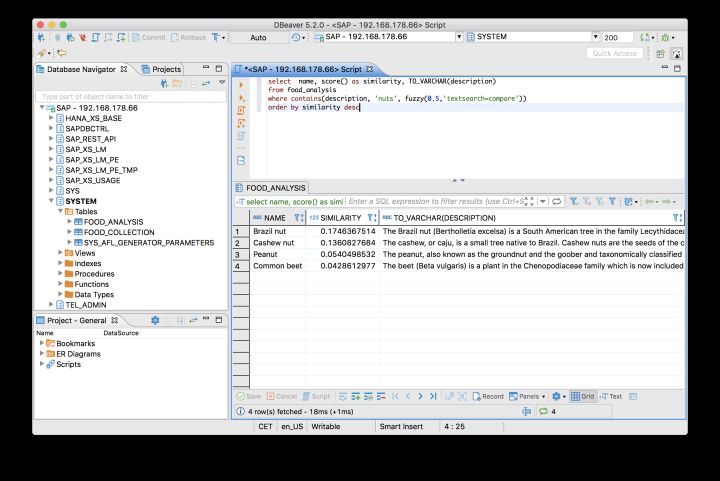
使用下列的SQL语句对描述字段进行模糊搜索:
选择名字,得分()相似,TO_VARCHAR(描述)从food_analysis包含(描述,& # 39;坚果# 39;,模糊(0.5 & # 39;textsearch=比较# 39;))命令相似desc
执行结果:
HANA Express Edition里的语言文本分析步骤也比较简单。
首先还是创建一个数据库表:
创建列表food_sentiment (nvarchar(64)主键名称,描述nvarchar (2048));
将文档存储里的JSON数据拷贝到数据库表里:
插入food_sentiment与doc_store(选择“name",“description"从food_collection)选择doc_store !”name"干净自己的名字,doc_store description"从doc_store描述;
针对描述字段创建一个新的指数:
创建全文索引FOOD_SENTIMENT_INDEX alt="怎么在SAP HANA Express Edition里进行文本分析">
由此可以发现,之前我们导入到数据库表里的英文句子,被HANA文本引擎拆解成单词,并且每个单词的词性也自动被HANA解析出来了。