
麋鹿日志文件分析系统基本部署
麋鹿概述
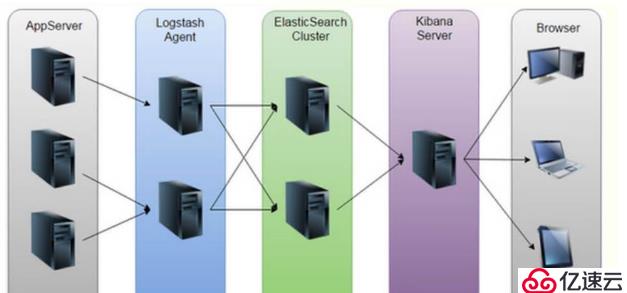
?麋鹿是elasticsearch, Logstashh和Kibana三个系统的首字母组合。当我们部署集群服务器的时候,日志文件就会散落在多台服务器上。查看日志信息就需要到各个服务器上去取和查看,我们把这些日志文件归集到一个地方统一管理。
<强> Elasticsearch 是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,宁静的风格接口,多数据源,自动搜索负载等。
<强> Logstash 是一个完全开源的工具,他可以对你的日志进行收集,过滤,并将其存储供以后使用(如,搜索)。
<强> Kibana 强也是一个开源和免费的工具,Kibana可以为Logstash和ElasticSearch提供的日志分析友好Web界的面,可以帮助您汇总,分析和搜索重要数据日志。
实验前期准备
名称 角色 地址 centos 7 - 1 node1 + kibana 192.168.142.221 centos 7 - 2 node1 192.168.142.132 centos 7胜 Logstash +网络 192.168.142.136这里我将WEB端与日志文件系统安装在了,各位可以根据个人情况,全部独立出去。(虚拟机开太多了,电脑顶不住啊)
实验步骤
一、部署Elasticsearch服务
注意:两个节点操作相同
<强>添加域名解析。方便后期使用
<代码类="语言java "> root@node1 ~ # vim/etc/hosts//添加 192.168.142.221 node1 192.168.142.132 node2JAVA版<>强检查本(没有安装的可以使用yum安装JAVA进行安装)
<代码类="语言java "> root@node1 ~ # java - version openjdk版本“1.8.0_131” OpenJDK运行时环境(构建1.8.0_131-b12) OpenJDK 64位服务器虚拟机(构建25.131 b12,混合模式)<强>部署elasticsearch服务(端口号:9200)
<代码类="语言java ">//部署elasticsearch服务 (root@node1 ~) # rpm -ivh elasticsearch-5.5.0.rpm//加载系统服务 (root@node1 ~) # systemctl daemon-reload (root@node1 ~) # systemctl启用elasticsearch.service<>强修改ES配置文件
<代码类="语言java "> root@node1 ~ # vim/etc/elasticsearch/elasticssearch.yml//以下几行取消注释 17/cluster.name: my-elk-eluster//集群名字(所有节点必须一样) 23/node.name: node1//节点名字(每个节点不同) 33/路径。数据:/数据/elk_data//数据存放路径 37/路径。日志:/var/log/elasticsearch///日志存放路径 43/引导。memorylock:假//不在启动的时候锁定内存 55/网络。主持人:0.0.0.0//提供服务绑定的IP地址,0。0. 0. 0代表所有地址 59/http。端口:9200//侦听端口为9200 68/discovery.zen.ping.unicast。主持人:[“node1”、“node2”]//集群发现通过单播实现<>强建立数据文件存放目录,并开启服务
<代码类="语言java "> [root@node1 ~] # mkdir - p/数据/elk_data (root@node1 ~) # chown - r elasticsearch: elasticsearch/数据/elk_data//修改属主属组 (root@node1 ~) # systemctl elasticsearch.service开始 (root@node1 ~) # netstat -atnp | grep 9200<强>验证服务是否开启
使用宿主机浏览器访问:http://192.168.142.132:9200 <代码>
{
“name":“node1",
“cluster_name":“my-elk-cluster",
“cluster_uuid":“mi3-z72CRqS-ofc4NhjXdQ",
“version":{
“number":“5.5.0",
“build_hash":“260387 d",
“build_date":“2017 - 06 - 30 - t23:16:05.735z"
“build_snapshot":假的,
“lucene_version":“6.6.0"
},
“tagline":“你知道,Search"
}二、安装管理插件elasticsearch-head(端口:9100)
注意:两个节点操作相同
<>强解压并编译安装
<代码类="语言java "> [root@node1 ~] # yum安装gcc gcc-c + + - y//安装节点组件包 (root@node1 ~) #焦油zxf node-v8.2.1.tar。广州- c/opt//在节点目录中 root@node1 ~ # ./configure (root@node1 ~) #//异常费时,大概耗时20分钟 (root@node1 ~) # make install麋鹿日志文件分析系统基本部署(纯实战)




