本篇内容主要讲解“Hadoop集群安装详细步骤”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Hadoop集群安装详细步骤”吧!
码头工人安装Hadoop集群
一、<强> <代码>单机Hadoop代码
首先进入我们已有容器:(码头工人exec -名(名字)命令/bin/bash)
mkdir/usr/hadoop
Cd/usr/hadoop
解压上传来的Hadoop,或wget获取http://mirrors.sonic.net/apache/hadoop/common/hadoop-2.8.3/hadoop-2.8.3.tar.gz
命令:焦油xvzf压缩包(小编一般解压完直接删除压缩包)
准备工作已完成,开始搭建Hadoop
编辑. bashrc
第六~/. bashrc
加入如下内容:
1。#设置Hadoop-related环境变量
export HADOOP_HOME=/usr/地方/hadoop
,
2。#添加Hadoop bin/目录路径
出口路径:$ PATH=$ HADOOP_HOME/sbin: $ HADOOP_HOME/bin
刷新一下:
~/来源。bashrc
此处有坑:
找不到which的话执行:yum install which
创建三个文件:
先进cd/usr/local/hadoop/hadoop-2.7.2
mkdir tmp作为Hadoop的临时目录
mkdir datanode作为NameNode的存放目录
mkdir namenode作为DataNode的存放目录
配置文件:cd/usr/local/hadoop/hadoop-2.7.2/etc/hadoop
三个文件:
1.core-site.xml配置:
2.hdfs-site.xml配置:(一些配置为了集群而准备)
3.mapred-site.xml配置:(有个mapred-site.xml.template文件,更改为mapred-site.xml)
下面就指定JAVA_HOME环境变量:
使用命令vi hadoop-env.sh,添加如下配置:
要使用的java实现。
<>之前,,,,,,,,,,,,export JAVA_HOME=/usr/java/jdk1.8.0_141接着格式化namenode
执行命令:hadoop namenode格式
此刻hadoop配置就完成了。
二,<强> <代码>安装SSH :
使用yum:,,,yum安装passwd openssl openssh服务器- y
因为我们是码头工人操作,他并不会自动启动,所以我们去给他加到. bashrc中
执行命令添加如下内容:Vi ~/ashrc
#自动运行(
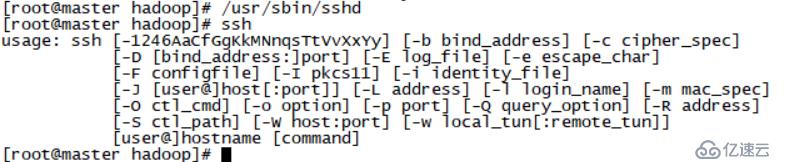
/usr/sbin/sshd
执行命令生成秘钥公钥:
ssh - keygen rsa - p - t & # 39; & # 39;- f ~/sh/id_dsa
cd ~/sh/
猫id_dsa。酒吧在祝辞authorized_keys
chmod 700 ~/sh/
chmod 600 ~/sh/authorized_keys
补:
无密登录问题:bash: ssh:命令没有找到
解决办法:yum - y安装openssh-clients
到此位置我们保存容器为新的镜像即可:
码头工人commit - m“hadoop install"61 c9cf8da12f linux: hadoop
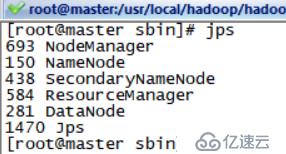
此时我们已经装好了一个单机版的hadoop镜像
<>强检测ssh :
命令1./usr/sbin/sshd
命令2。ssh
三,<强> <代码>码头工人Hadoop集群 :
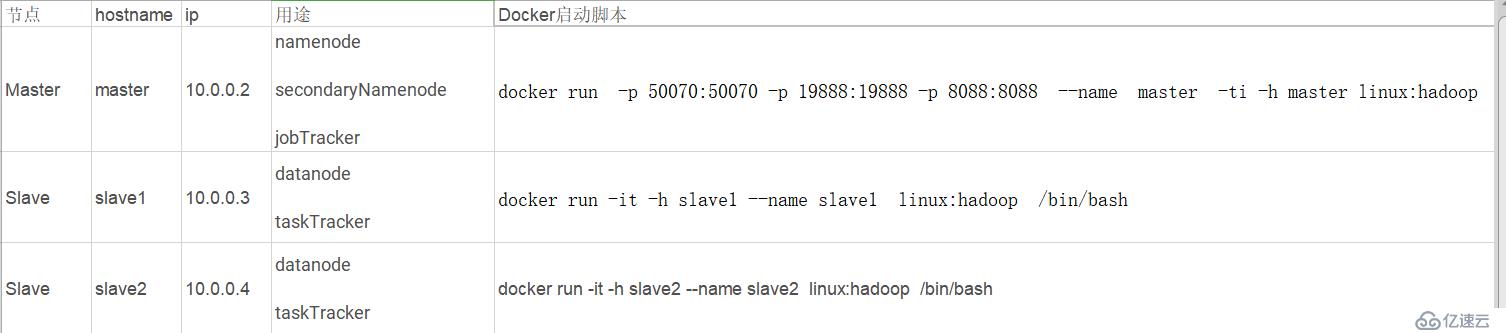
切记:主机名、主机配置在容器内修改了,只能在本次容器生命周期内有效。如果容器退出了,重新启动,这两个配置将被还原。且这两个配置无法通过提交命令写入镜像。
三个容器启动后分别配置主机第六
/etc/hosts,注意修改ip地址:
172.17.0.2 ,,,,,的主人 172.17.0.3 ,,,, slave1 172.17.0.4 ,,,, slave2 启动sshd ,/usr/sbin/sshd
配置奴隶:vi/usr/local/hadoop/hadoop-2.7.2/etc/hadoop/
将奴隶:主
slave1
slave2
添加进去之后:

主如下: