
这篇文章主要介绍”直方图的工作原理以及分位数的计算方法”,在日常操作中,相信很多人在直方图的工作原理以及分位数的计算方法问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答“直方图的工作原理以及分位数的计算方法”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
普罗米修斯中提供了四种指标类型(参考:普罗米修斯的指标类型),其中直方图(柱状图)和摘要(总结)是最复杂和难以理解的,这篇文章就是为了帮助大家加深对这<代码>直方图>
1。什么是直方图?
根据上篇文档,直方图会在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中。但这句话还是不太好理解,下面通过具体的示例来说明。
假设我们想监控某个应用在一段时间内的响应时间,最后监控到的样本的响应时间范围为0 ~ 10。现在我们将样本的值域划分为不同的区间,即不同的<代码>叶片>
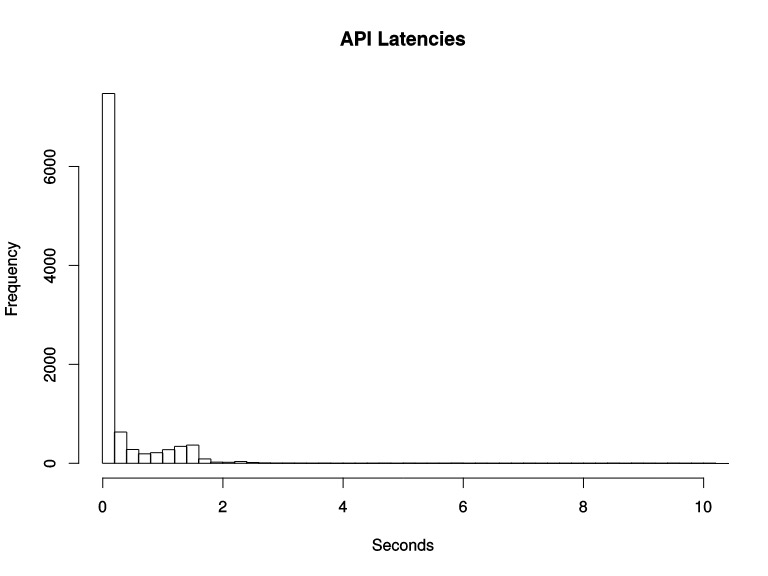
普罗米修斯的直方图是一种累积直方图,与上面的区间划分方式是有差别的,它的划分方式如下:还假设每个桶的宽度是0.2秒,那么第一个桶表示响应时间小于等于0.2秒的请求数量,第二个桶表示响应时间小于等于0.4秒的请求数量,以此类推。也就是说,<强>每一个桶的样本包含了之前所有桶的样本强,所以叫累积直方图。
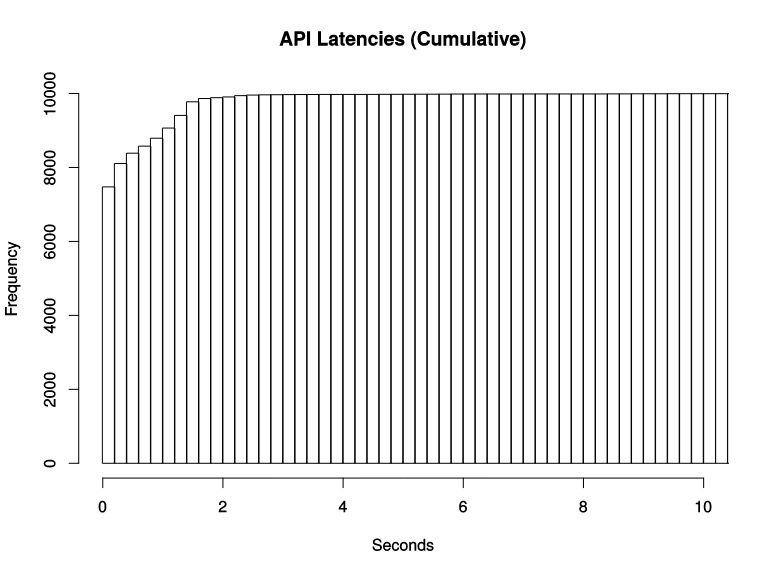
2。为什么是累积直方图?
上节内容告诉我们,普罗米修斯中的直方图是累积的,这是很奇怪的,因为通常情况下非累积的直方图更容易理解.Prometheus为什么要这么做呢?
想象一下,如果直方图类型的指标中加入了额外的标签,或者划分了更多的水桶,那么样本数据的分析就会变得越来越复杂。如果直方图是累积的,在抓取指标时就可以根据需要丢弃某些桶,这样可以在降低普罗米修斯维护成本的同时,还可以粗略计算样本值的分位数。通过这种方法,用户不需要修改应用代码,便可以动态减少抓取到的样本数量。
假设某个直方图类型指标的样本数据如下:
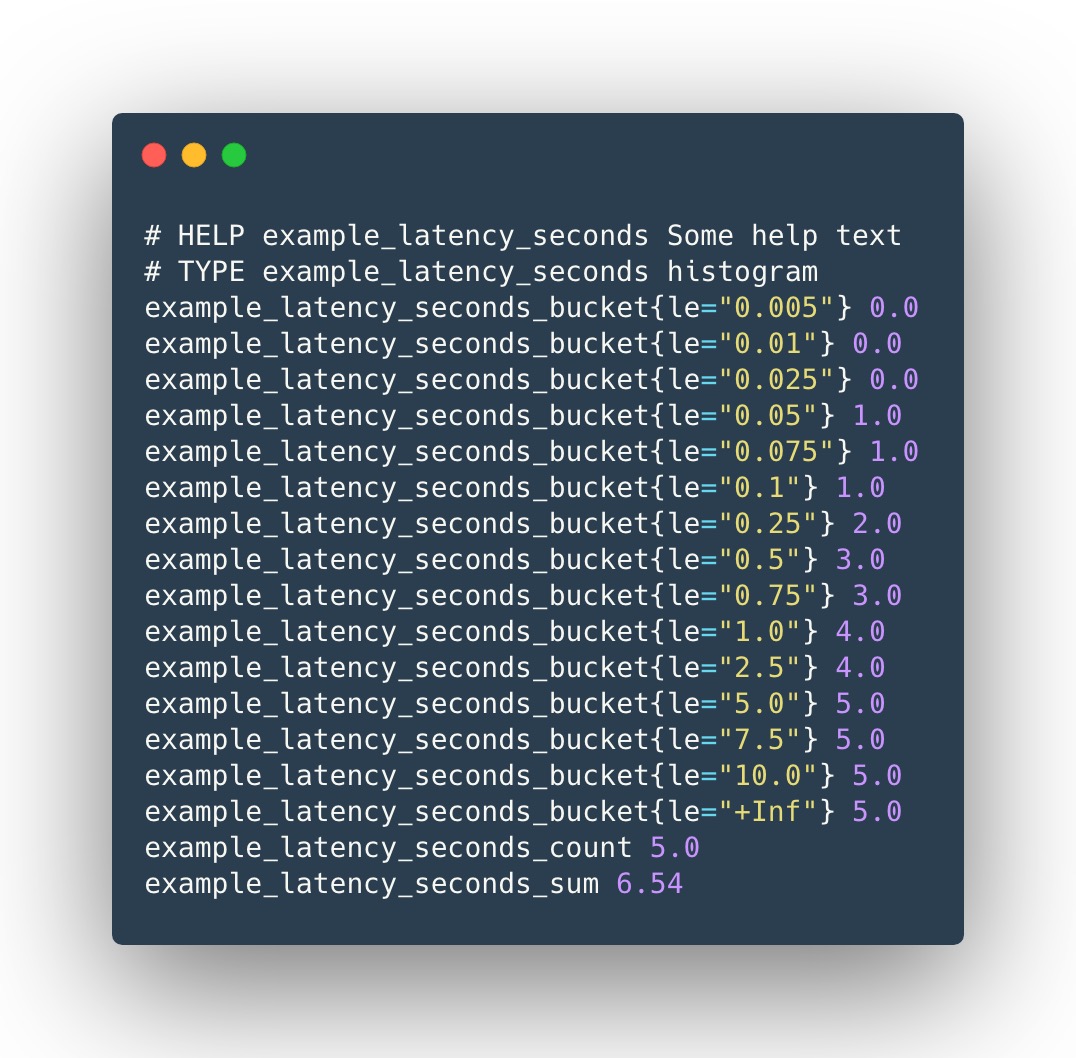
现在我们希望普罗米修斯在抓取指标时丢弃响应时间在<代码> 100 ms>
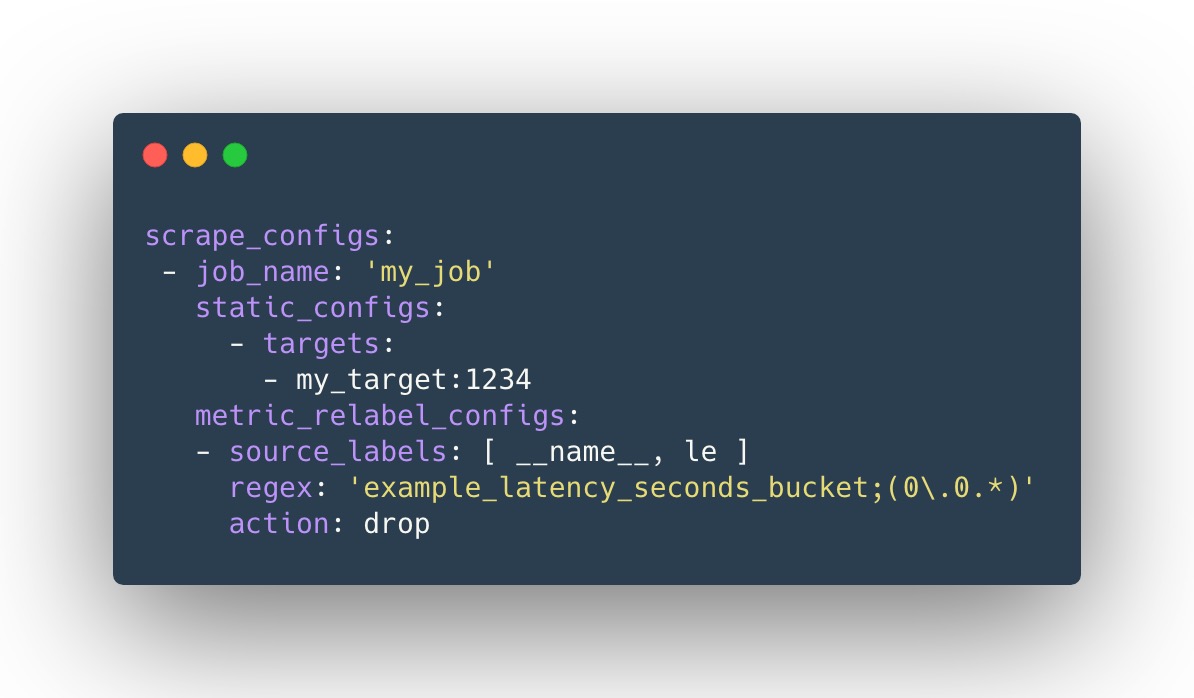
其中,<代码> example_latency_seconds_bucket> __name__> le> le> 0.0 x>
通过这种方法,你可以丢弃任意的桶,但不能丢弃<代码>勒=? Inf"> histogram_quantile 函数需要使用这个标签。
另外直方图还提供了<代码> _sum> _count>
通过累积直方图的方式,还可以很轻松地计算某个桶的样本数占所有样本数的比例。例如,想知道响应时间小于等于1 s的请求占所有请求的比例,可以通过以下公式来计算:
example_latency_seconds_bucket{勒=?.0“},/,ignoring (le), example_latency_seconds_bucket{勒=? Inf"} 3。分位数计算
普罗米修斯通过<代码> histogram_quantile 函数来计算分位数(分位数),而且是一个预估值,并不完全准确,因为这个函数是假定每个区间内的样本分布是线性分布来计算结果值的。预估的准确度取决于桶区间划分的粒度、粒度越大,准确度越低。以下图为例:
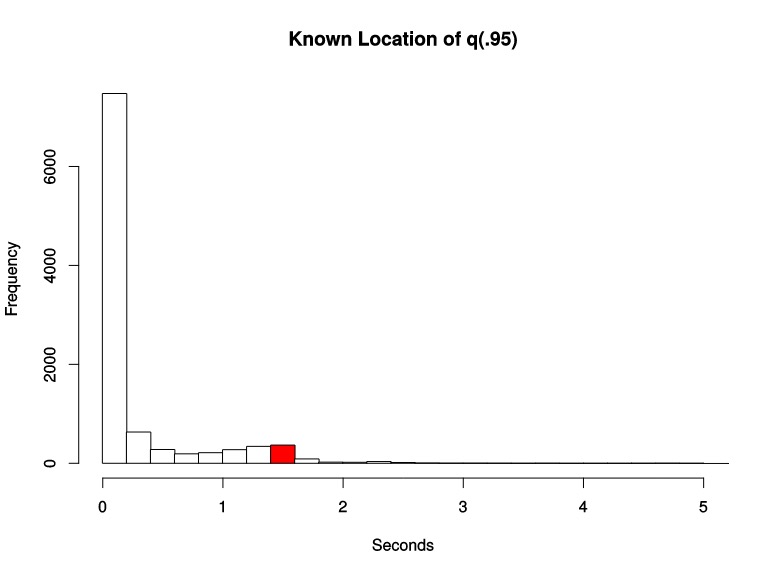
假设有<代码> 10000个样本,第<代码> 9501个样本落入了第8个桶。第8个桶总共有




