
如何理解MongoDB中的碎片分片,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
阅读目的:深刻的了解MongoDB的分片机制
阅读关键:无比要对MongoDB的与分片碎片有关的概念有清楚的了解。
, 1:,碎片介绍
,,,,,,,,碎片指的是水平方向的多节点的数据分散的存储,说的更简单一点,就是一台机器上可能装不下的数据,我们
装到多台机器上的去,比如,我们将全国的省份证的信息,存储到不同的碎片服务器中间去,这里的碎片服务器,就是每一个分布式的Mongo机器。
,,,,,,,,应用的程序可以通过蒙戈过程登陆到碎片集群之中,MongoPress进行一个路由上的调度。查询,请求的过程也是如此。面对使用者只有一层一个节点。
,,,,
2:负载均衡和失效切换
,,,,,,,,当某个碎片的负载超过一定阙值后,就会自动的重新分发数据,用来保证系统的负载均衡。更简单的话来形容,就是
写入的时候如果向某一台机器上去写,超过了机器自身的能力了,就会重新的分发数据,与之对应的Hbase,通常会出现单台
写入的热点问题,目前对于蒙戈的处理机制还未知。
,,,,,在一个通常的配置之中,每一个碎片中都该包含了2个以上节点的设备组,设备组的名字通常称为replica.set, replica.set有N台服务器,在其中有一个为主,其他的为辅助,一旦其中的一个挂掉以后,会自动重启将一台服务器切换为
主服务器。
3:
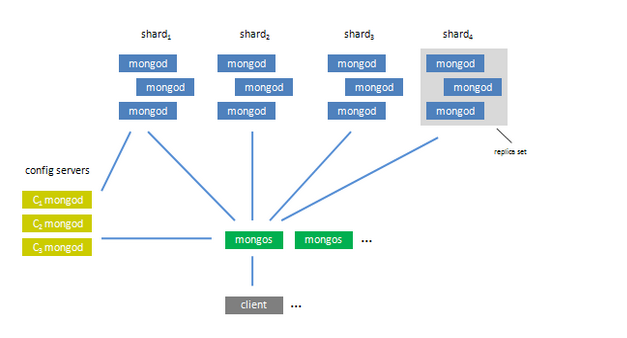
,,,,碎片架构图:
,,,,,,,, 
4:切分key
,,,,,,,,,,,,要实现分片功能,我们需要指定集合的分片钥匙,相当于数据库的分区字段,
这个分片关键通常需要创建一个索引,分片关键可以由一个或则多个字段构成
5:
块,,,,,,,,块是一个集合之中的一段连续的数据,当一个块达到一定大小的时候,就会开始分裂。当一个
碎片超过一定量的数据时,一部分会被迁移到其他碎片之中,新增碎片也会影响块的移动,好比你把日志
写入到你的本地文件,规定是60米的一个文件,一旦超过大小,就有新的文件,一旦文件在机器上存放不了的了,
那就将这台机器上的文件转移到其他的机器上去~,,,,,
,MongoDB的碎片,四环一种将海量的数据水平扩展的数据库集群系统,数据库分表存放在分片的
各个节点之上。
相对于关系数据库而言,就大部分是数据库中的一行记录,就集合是对于与关系数据库中的表。
即碎片服务器存储实际数据的分片,每个碎片可以是一个mongod实例,也可以是一组mongod实例构成的副本集。为了实现每个碎片内部的auto-failover, MongoDB官方建议每个切分为一组副本集。关于如何安装及搭建副本集请参考我的另一篇文章http://gong1208.iteye.com/blog/1558355
配置服务器为了将一个特定的集合存储在多个碎片中,需要为该集合指定一个分片键,例如{年龄:1},分片键可以决定该条记录属于哪个chunk.Config服务器就是用来存储:所有碎片节点的配置信息,每个大块的碎片关键范围,块在各碎片的分布情况,该集群中所有DB和收集的分片配置信息。
说的更加明白一点,配置服务器保存集群的元数据。
路由过程这是一个前端路由,客户端由此接入,然后询问配置服务器需要到哪个碎片上查询或保存记录,再连接相应的碎片进行操作,最后将结果返回给客户端。客户端只需要将原本发给mongod的查询或更新请求原封不动地发给路由过程,而不必关心所操作的记录存储在哪个碎片上。
路线过程说的更明白点就是一个选择器,不断的调度合适的客户端请求,将需求中所请求,所需要的数据,从合适的碎片之中返回你所需求的数据。
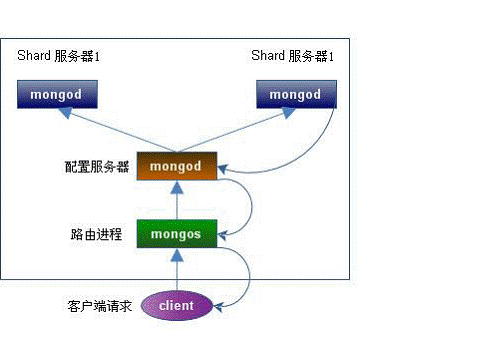
下面我们在同一台物理机器上构建一个简单的分片集群:
架构图如下:
,,,
关于如何理解MongoDB中的碎片分片问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注行业资讯频道了解更多相关知识。




