
本篇文章为大家展示了如何理解Lucene的简介与索引过程,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
Lucene的介绍与使用
Lucene是Doug Cutting利用周末时间所开发的全文检索引擎,Doug Cutting主导开发了Lucene与Nutch,而基于Nutch中分离出的Hadoop在雅虎成立Hadoop项目组,继续主导推动Hadoop的研发.Lucene不是一个应用软件,而是类似于一个全文检索的函数库,他为应用软件提供了基础了函数接口,实现文档到检索的API。
<人力资源/> <编辑>首先考虑数据类型问题。
1。结构化数据能够具有固定的格式,长度的数据。如数据库。
2。非结构化数据数据无定长,无严格的格式划分,无模式信息等。如日志,邮件,文档等。
解决非结构化的数据检索的问题数据库方式也可以。但是效率较低。那么对于该类日志的使用场景基本上属于基于内容的检索。全文检索的应用场景问题
<编辑>
1。日志分析:对于没有定义详细结构的日志数据的分析,例如基于关键词查询。(当前我司的日志数据就是这种方式,日志输出较为随意,通过某些关键词进行检索日志中的异常问题)
2。搜索引擎搜索:搜索引擎的全文检索是典型的场景,同样是通过关键词来检索到爬虫抓取到的网页,文档等相关内容
3。电商搜索:对于电商站内的商品进行基于类别,标题,内容的相关性商品的检索等
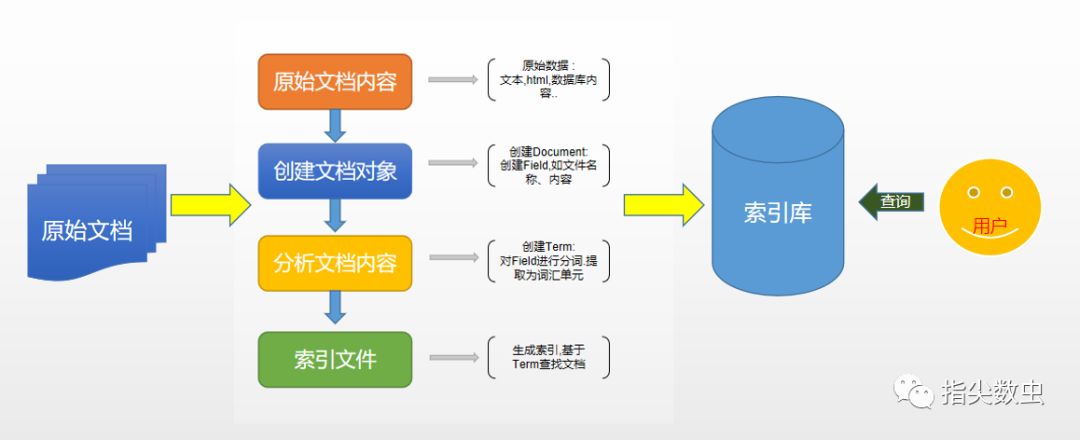
<标记>基于上图得到如果需要使用Lucene进行全文检索的整体流程。
基于上图分解
<李>
原始文档:
<李>
原始文档可以是网页,邮件,词文档等内容。那么Lucene不提供相关的网页数据的抓取,但是Doug Cutting开发了Nutch提供了网络爬虫的功能。下面介绍一些常见的爬虫工具
1.1: Nutch: Doug Cutting开发的网络爬虫工具,实现分布式网页数据采集功能。
1.2: Scrapy: Python领域专业的爬虫开发框架,已经完成了常用的爬虫工具。
1.3: WebMagic: Java方向基于Scrapy的思想开发的网络爬虫库,在Java方向有非常高的人气。…创建文档对象:
<李>
创建文档对象是为了能够实现检索即可获得到该文档内容,例如搜索引擎搜索,<标记>“PHP是世界上最好的语言“标记,即可获取到某篇网页内容,网页内容即可定义为文档对象。那么这里我们就把一个网页定义为一个文档对象(文档),每个文档对象中又包含各种的字段(标题,内容,时间,作者等)。当然在网页采集中尽量提取能够获取到的领域,而类似于谷歌,百度等都会有相应的规则,能够让爬虫程序识别到哪里是标题,内容等。但是每个文档都会有唯一的地址,例如网页的网址分析文档内容:
分析文档内容即把文档中的各种领域中的内容进行分析,进行分词,大小写转换,特殊符号过滤,去除停用词等使其生成最终的词汇单元,也就是一个个的单词。
比如:
<标记> PHP是世界上最好的语言标记
分词后的词汇单元为:
PHP,世界上,最好,语言每个单词叫做项,不同的文档,场中拆分出不同的Term.Term中包含DOcumentID与单词内容。
<李>创建索引:
TemrsDocumentIdPHPdoc_1, doc_2, doc_3世界doc_1, doc_3语言doc_2, doc_3李
创建索引的目的是为了检索到相关的文档,所以全文检索最终的术语,其实最终要定位到一个文档。那么简单来想索引库中包含的词基本上会有多个DOcumentID用来定位该术语可检索到的文档。
简单的可以为:至此Lucene的索引即构建完成,索引库建立即可通过Lucene提供的检索Api进行数据的检索。
上述内容就是如何理解Lucene的简介与索引过程,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注行业资讯频道。
如何理解Lucene的简介与索引过程




