
这期内容当中小编将会给大家带来有关Hadoop2.2.0中的高可用性实现原理是什么,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
在Hadoop2.0.0之前,NameNode (NN)在HDFS集群中存在单点故障(单点故障),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到神经网络重启或者在另一台主机上启动NN守护线程。
主要在两方面影响了HDFS的可用性:
(1),在不可预测的情况下,如果NN所在的机器崩溃了,整个集群将无法利用,直到神经网络被重新启动;
(2),在可预知的情况下,比如神经网络所在的机器硬件或者软件需要升级,将导致集群宕机。
HDFS的高可用性将通过在同一个集群中运行两个神经网络(NN活跃,备用NN)来解决上面两个问题,这种方案允许在机器破溃或者机器维护快速地启用一个新的神经网络来恢复故障。
在典型的HA集群中,通常有两台不同的机器充当神经网络。在任何时间,只有一台机器处于活跃的状态,另一台机器是处于待机状态.Active NN负责集群中所有客户端的操作,而备用NN主要用于备用,它主要维持足够的状态,如果必要,可以提供快速的故障恢复。
为了让备用NN的状态和活跃的NN保持同步,即元数据保持一致,它们都将会和JournalNodes守护进程通信。当活跃NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上(通过编辑日志持久化存储),而备用NN负责观察编辑日志的变化,它能够读取从发展期中读取编辑信息,并更新其内部的命名空间,一旦活跃NN出现故障,备用神经网络将会保证从发展期中读出了全部的编辑,然后切换成活跃的状态.Standby NN读取全部的编辑可确保发生故障转移之前,是和活跃的NN拥有完全同步的命名空间状态。
为了提供快速的故障恢复,备用NN也需要保存集群中各个文件块的存储位置。为了实现这个,集群中所有的数据库将配置好活跃NN和备用NN的位置,并向它们发送块文件所在的位置及心跳,如下图所示:
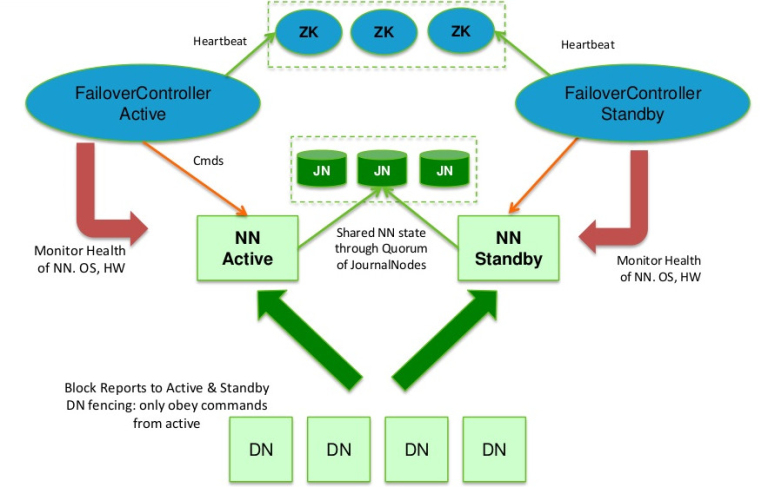
Hadoop2.2.0中HDFS的高可用性实现原理
在任何时候,集群中只有一个神经网络处于活跃的状态是极其重要的。否,则在两个活动,NN的状态下名称空间状态将会出现分歧,这将会导致数据的丢失及其它不正确的结果。为了保证这种情况不会发生,在任何时间,发展期只允许一个NN充当作家。在故障恢复期间,将要变成活跃的状态的神经网络将取得作家的角色,并阻止另外一个神经网络继续处于活跃的状态。
为了部署HA集群,你需要准备以下事项:
(1), NameNode机器:运行积极NN和备用NN的机器需要相同的硬件配置;
(2), JournalNode机器:也就是运行约的机器.JN守护进程相对来说比较轻量,所以这些守护进程可以可其他守护线程(比如尼龙、纱ResourceManager)运行在同一台机器上。在一个集群中,最少要运行3个约守护进程,这将使得系统有一定的容错能力。当然,你也可以运行3个以上的约,但是为了增加系统的容错能力,你应该运行奇数个约(3、5、7等),当运行N个约,系统将最多容忍(N - 1)/2个约崩溃。
在HA集群中,备用NN也执行名称空间状态的检查点,所以不必要运行二级神经网络,CheckpointNode和备份节点;事实上,运行这些守护进程是错误的。
上述就是小编为大家分享的Hadoop2.2.0中的高可用性实现原理是什么了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注行业资讯频道。




