
介绍
这篇文章给大家介绍kafka-Storm中如何将日志文件打印到当地,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
阅读前提:
,,,,,,,, 1:您可能需要对,logback日志系统有所了解
,,,,,,2:您可能需要对于,卡夫卡有初步的了解
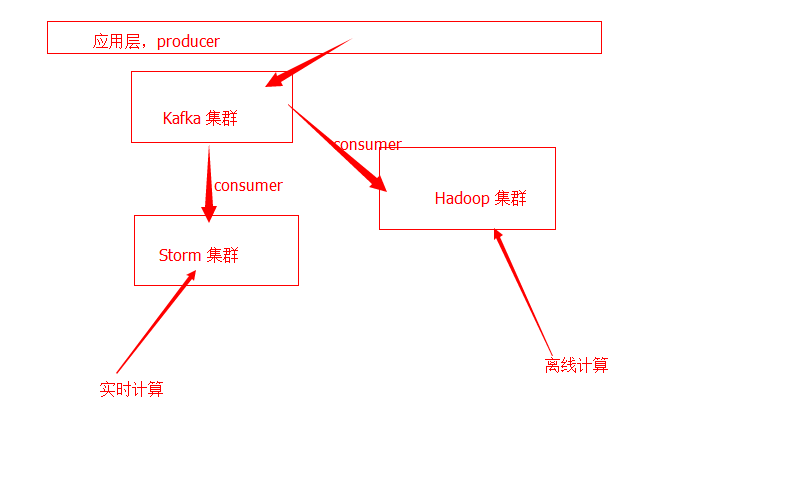
,,,,,,3:请代码查看之前,请您仔细参考系统的业务图解
,,,,由于卡夫卡本身自带了和“Hadoop的接口,如果需要将卡夫卡中的文件直接迁移到HDFS,请参看本ID的另外一篇博文:
,,,,,,,,业务系统-kafka-Storm【日志本地化】- 2:直接通过卡夫卡将日志传递到HDFS
,,1:一个正式环境系统的系统设计图解:
,,,,,,,,,,,,,, , topicCountMap =, new HashMap<字符串,,Integer> ();
topicCountMap.put (_topic, new 整数(1));
字符串,Map
, topicCountMap =, new HashMap<字符串,,Integer> ();
topicCountMap.put (_topic, new 整数(1));
字符串,Map




