
小编给大家分享一下怎么用Eclipse开发Spark2.0,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获、下面让我们一起去了解一下吧!
1。首先我用的是scala版本的ide。,这个可以去官网下载。先介绍下我的版本:hadoop2.7.2 + spark2.0 + scala2.11 + java1.7
首先打开eclipse,设置好工作区后,就能开始开发了
2。新建scala项目,,起个项目的名字
3。新建个scala对象,。开始写代码
注意需要导入相关的包。主要有scala的包还有火花的包,火花需要的包主要在火花安装目录下的jar文件下的所有包
4。废话少说,直接上代码
对象TestSparkStreaming {
,def主要(args:数组[String]):单位={
,,进口org.apache.spark。_
,,进口org.apache.spark.streaming。_
,,进口org.apache.spark.streaming.StreamingContext。_//没有必要因为火花
1.3,,//创建一个本地StreamingContext两个工作线程和批间隔1秒。
,,//主需要2核阻止饥饿场景。
,,配置=new SparkConf瓦尔().setMaster(“本地[2]“).setAppName (“NetworkWordCount")
,,val ssc=new StreamingContext(参看,秒(5))
,,val行=ssc.socketTextStream (“master", 9999)
,,//val行=ssc.textFileStream (“/home/usr/temp/?
,,val语言=lines.flatMap (_.split (““))
,,进口org.apache.spark.streaming.StreamingContext。_//没有必要因为火花1.3
,,//计数每个词在每一批
,,val双=单词。地图(词=比;(1)单词)
,,val wordcount=对。reduceByKey (_ + _)
,,//打印每个抽样的前十个元素生成这个DStream控制台
,,wordCounts.print ()
,,ssc.start()//开始计算
,,ssc.awaitTermination ()
,}
}
5。在linux中,终端连上9999端口,nc-lk, 9999
输入一些单词
6。可以看到eclipse的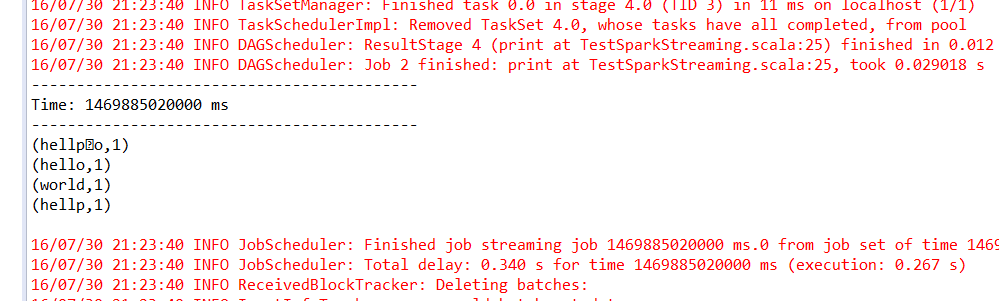 以上是“怎么用eclipse开发Spark2.0”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注行业资讯频道!
以上是“怎么用eclipse开发Spark2.0”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注行业资讯频道!




