
这篇文章给大家分享的是有关怎么用阿尔萨斯来诊断HBase异常进程的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
1。异常突起
HBase集群的某一个RegionServer的CPU使用率突然飙升到百分之百,单独重启该RegionServer之后,CPU的负载依旧会逐渐攀上顶峰。多次重启集群之后,CPU满载的现象依然会复现,且会持续居高不下,慢慢地该RegionServer就会宕掉,慢慢地HBase集群就完犊子了。
2。异常之上的现象
鼎晖监控页面来看,除CPU之外的几乎所有核心指标都是正常的,磁盘和网络IO都很低,内存更是充足,压缩队列,刷新队列也是正常的。
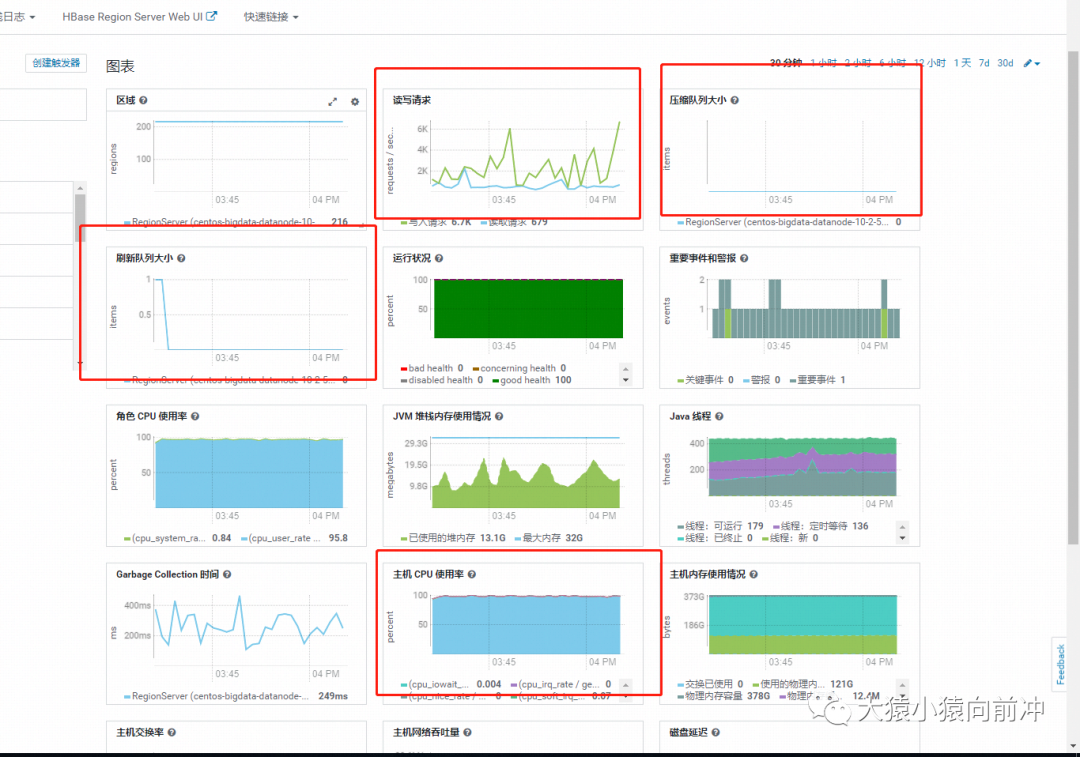
普罗米修斯的监控也是类似这样的,就不贴图了。
监控指标里的数字,只能直观地告诉我们现象,不能告诉我们异常的起因,因此我们的第二反应是看日志。
与此同时,日志中还有很多类似这样的干扰输出。

后来发现这样的输出只是一些无关紧要的信息,对分析问题没有任何帮助,甚至会干扰我们对问题的定位。
但是,日志中大量扫描responseTooSlow的警告信息,似乎在告诉我们,HBase的服务器内部正在发生着大量耗时的扫描操作,这也许就是CPU负载高的元凶。可是,由于各种因素的作用,我们当时的关注点并没有在这个上面,因为这样的信息,我们在历史的时间段里也频繁撞见。
3。初识阿尔萨斯
监控和日志都不能让我们百分百确定CPU负载高是由哪些操作引起的,我们用高级命令也只能看到HBase这个进程消耗了很多CPU,就像下图看到的这样。
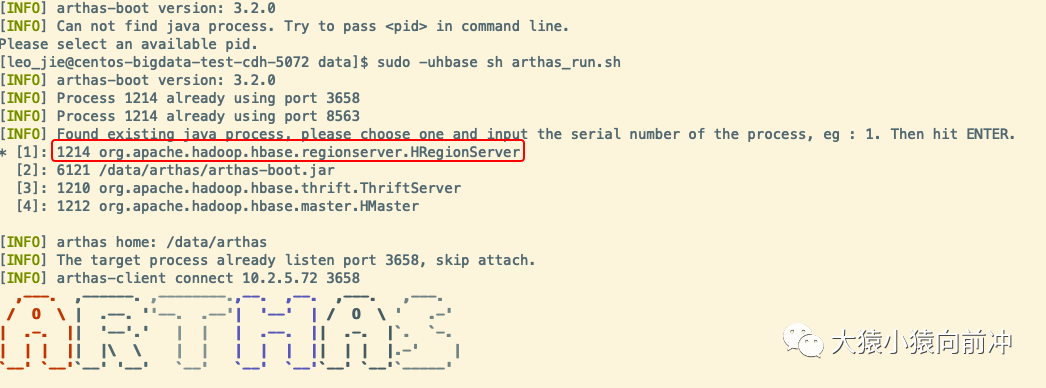
命令高层定位到的异常的HBase进程ID是1214年,该进程就是HRegionServer的进程。输入序1号,回车,就进入了监听该进程的命令行界面。
4.3仪表板

输入线程命令回车,查看该进程下所有线程的执行情况。
4.5线- n 3
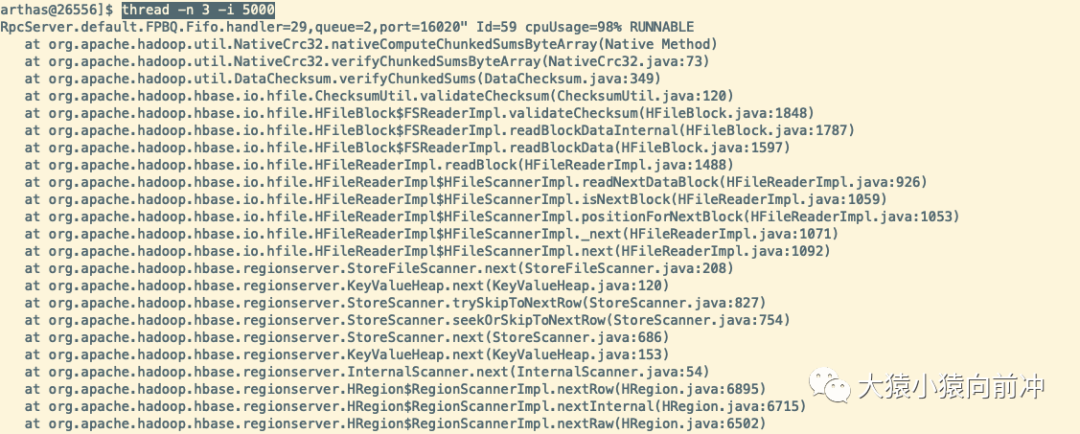
单位时间为5秒内,资源占用前三名的线程。
4.7使用async-profiler生成火焰图
生成火焰图的最简单命令。
profiler 开始
隔一段时间,大概三十秒。
profiler 停止
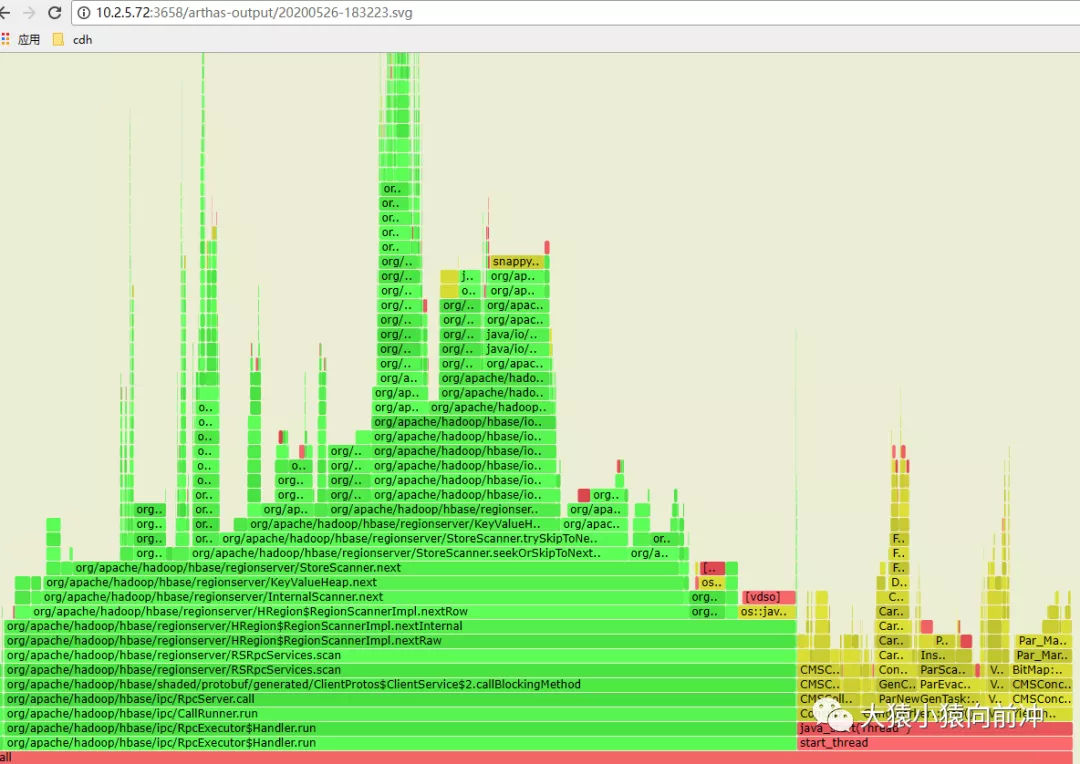
关于火焰图的入门级知识:
查看jvm进程CPU火焰图工具。
火焰图里很清楚地定位到CPU时间占用最高的线程是绿框最长的那些线程,也就是扫描操作。
5。扫描操作引起的CPU负载过高
通过以上的进程分析,我们最终可以确定,扫描操作的发生,导致CPU负载很高。我们查询HBase的API基于happybase封装而成。
其实常规的扫描操作是能正常返回结果的,发生异常查询的表也不是很大,所以我们排除了热点的可能。抽象出来业务方的查询逻辑是:
<>之前得到happybase.connection import Connectionimport 时间 时间=start time.time () 时间=con 连接(主机=& # 39;ip # 39;,,=9090港,超时=3000) 时间=table con.table (“table_name") 试一试: ,,,res =,列表(table.scan(过滤器=癙refixFilter (& # 39; 273810955 | & # 39;)“,,,,,,,,,,,,,,,,,,,,,,, row_start=& # 39; \ x0f \ x10& R \ xca \ xdf \ x96 \ xcb \ xe2 \ \ xad9khE \ x19美元xad7 \ xfd \ xaa \ x87 \ xa5 \ xdd \ xf7 \ x85 \ x1c \ x81ku ^ \ x92k& # 39;,,,,,,,,,,,,,,,,,,,,,,,限制=3)) except Exception as e: ,才能通过 最终获得=,time.time () print & # 39;超时:,% d # 39;, %,(最终获得成功,开始)PrefixFilter和row_start的组合是为了实现分页查询的需求,row_start的一堆乱码字符,是加密的一个user_id,里面有特殊字符。日志中看到,所有的耗时查询,都有此类乱码字符的传参于。是,我们猜想,查询出现的异常与这些乱码字符有关。
但是,后续测试复现的时候又发现。




