
这期内容当中小编将会给大家带来有关消息中间件Kafka、RocketMQ该怎么理解,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
消息中间件的应用场景
异步解耦
削峰填谷
顺序收发
分布式事务一致性
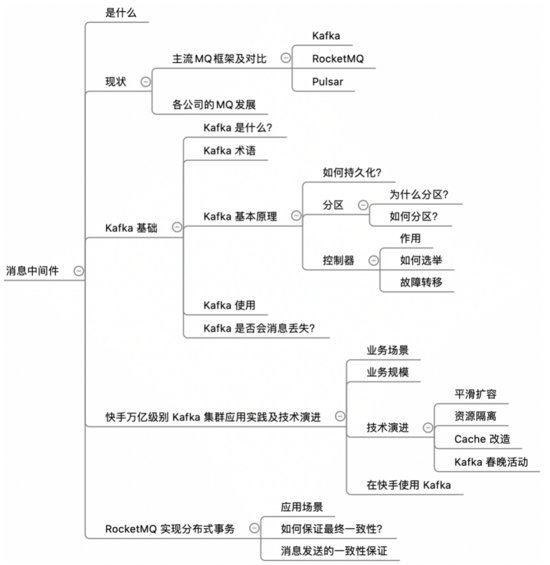
主流 MQ 框架及对比
说明
Kafka:整个行业应用广泛
RocketMQ:阿里,从 apache 孵化
Pulsar:雅虎开源,符合云原生架构的消息队列,社区活跃
RabbitMQ 架构比较老,AMQP并没有在主流的 MQ 得到支持
NSQ:内存型,不是最优选择
ActiveMQ、ZeroMQ 可忽略
Kafka 优点
非常成熟,生态丰富,与 Hadoop 连接紧密
吞吐非常高,可用性高sharding提升 replication 速度
主要功能:pub-sub,压缩支持良好
可按照 at least>
写入延时稳定性问题,partition 很多时Kafka 通常用机械盘,随机写造成吞吐下降和延时上升100ms ~ 500ms
运维的复杂性单机故障后补充副本数据迁移快手的优化:迁移 partition 时旧数据不动,新数据写入新 partition 一定时间后直接切换
RocketMQ
阿里根据 Kafka 改造适应电商等在线业务场景
以牺牲性能为代价增强功能安 key 对消息查询,维护 hash 表,影响 io为了在多 shard 场景下保证写入延迟稳定,在 broker 级别将所有 shard 当前写入的数据放入一个文件,形成 commitlog list,放若干个 index 文件维护逻辑 topic 信息,造成更多的随机读
没有中心管理节点,现在看起来并没有什么用,元数据并不多
高精度的延迟消息(快手已支持秒级精度的延迟消息)
Pulsar
存储、计算分离,方便扩容存储:bookkeeperMQ逻辑:无状态的 broker 处理
发展趋势
云原生
批流一体:跑任务时,需要先把 Kafka 数据→HDFS,资源消耗大。如果本来就存在 HDFS,能节省很大资源
Serverless
各公司发展
快手:Kafka所有场景均在使用特殊形态的读写分离数据实时消费到 HDFS在有明显 lag 的 consumer 读取时,broker 把请求从本地磁盘转发的 HDFS不会因为有 lag 的 consumer 对日常读写造成明显的磁盘随机读写由于自己改造,社区新功能引入困难
阿里巴巴:开源 RocketMQ
字节跳动在线场景:NSQ→RocketMQ离线场景:Kafka→自研的存储计算分类的 BMQ(协议层直接兼容Kafka,用户可以不换 client)
百度:自研的 BigPipe,不怎么样
美团:Kafka 架构基础上用 Java 进行重构,内部叫 Mafka
腾讯:部分使用了自研的 PhxQueue,底层是 KV 系统
滴滴:DDMQ对 RocketMQ 和 Kafka 进行封装多机房数据一致性可能有问题
小米:自研 Talos架构类似 pulsar,存储是 HDFS,读场景有优化
Kafka
Kafka官网: https://kafka.apache.org/documentation/#uses
最新版本:2.7
Kafka 是什么?
开源的消息引擎系统(消息队列/消息中间件)
分布式流处理平台
发布/订阅模型
削峰填谷
Kafka 术语
Topic:发布订阅的主题
Producer:向Topic发布消息的客户端
Consumer:消费者
Consumer Group:消费者组,多个消费者共同组成一个组
Broker:Kafka的服务进程
Replication:备份,相同数据拷贝到多台机器Leader ReplicaFollower Replica,不与外界交互
Partition:分区,解决伸缩性问题,多个Partition组成一个Topic
Segment:partition 有多个 segment 组成




