
怎么在Linux中使用叉()函数?相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
<强>,一,fork()函数
在操作系统的基本概念中进程是程序的一次执行,且是拥有资源的最小单位和调度单位(在引入线程的操作系统中,线程是最小的调度单位)。在Linux系统中创建进程有两种方式:一是由操作系统创建,二是由父进程创建进程(通常为子进程)。系统调用函数fork()是创建一个新进程的唯一方式,当然vfork()也可以创建进程,但是实际上其还是调用了fork()函数.fork()函数是Linux系统中一个比较特殊的函数,其一次调用会有两个返回值、下面是fork()函数的声明:
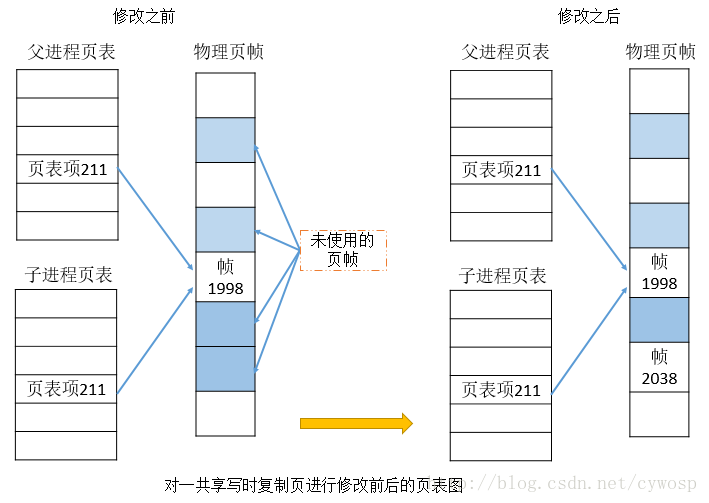
当程序调用fork()函数并返回成功之后,程序就将变成两个进程,调用fork()者为父进程,后来生成者为子进程。这两个进程将执行相同的程序文本, 但却各自拥有不同的栈段、数据段以及堆栈拷贝。子进程的栈、数据以及栈段开始时是父进程内存相应各部分的完全拷贝,因此它们互不影响。从性能方面考虑,父 进程到子进程的数据拷贝并不是创建时就拷贝了的,而是采用了写时拷贝(copy-on -write)技术来处理。调用fork()之后,父进程与子进程的执行顺序是我们无法确定的(即调度进程使用CPU),意识到这一点极为重要,因为在一些设计不好的程序中会导致资源竞争,从而出现不可预知的问题。下图为写时拷贝技术处理前后的示意图:
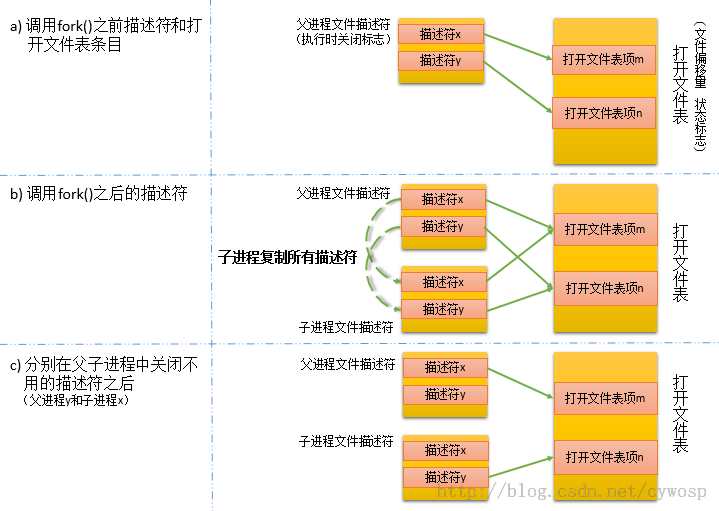
在Linux系统中,常常存在许多对文件的操作,fork()的执行将会对文件操作带来一些小麻烦。由于子进程会将父进程的大多数数据拷贝一份,这样在文 件操作中就意味着子进程会获得父进程所有文件描述符的副本,这些副本的创建方式类似于dup()函数调用,因此父、子进程中对应的文件描述符均指向相同的 打开的文件句柄,而且打开的文件句柄包含着当前文件的偏移量以及文件状态标志,所以在父子进程中处理文件时要考虑这种情况,以避免文件内容出现混乱或者别 的问题。下图为执行fork()调用后文件描述符的相关处理及其变化:
二、线程
与进程类似,线程(thread)是允许应用程序并发执行多个任务的一种机制。一个进程中可以包含多个线程,同一个程序中的所有线程均会独立执行,且共享 同一份全局内存区域,其中包括初始化数据段(initialized data),未初始化数据段(uninitialized data),以及堆内存段(heap segment)。在多处理器环境下,多个线程可以同时执行,如果线程数超过了CPU的个数,那么每个线程的执行顺序将是无法确定的,因此对于一些全局共 享数据据需要使用同步机制来确保其的正确性。
在系统中,线程也是稀缺资源,一个进程能同时创建多少个线程这取决于地址空间的大小和内核参数,一台机器可以同时并发运行多少个线程也受限于CPU的数 目。在进行程序设计时,我们应该精心规划线程的个数,特别是根据机器CPU的数目来设置工作线程的数目,并为关键任务保留足够的计算资源。如果你设计的程 序在背地里启动了额外的线程来执行任务,那这也属于资源规划漏算的情况,从而影响关键任务的执行,最终导致无法达到预期的性能。很多程序中都存在全局对 象,这些全局对象的初始化工作都是在进入main()函数之前进行的,为了能保证全局对象的安全初始化(按顺序的),因此在程序进入main()函数之前 应该避免线程的创建,从而杜绝未知错误的发生。
三、fork()与多线程
在程序中fork()与多线程的协作性很差,这是POSIX系列操作系统的历史包袱。因为长期以来程序都是单线程的,fork()运转正常。当20世纪90年代初期引入线程之后,fork()的适用范围就大为缩小了。
在多线程执行的情况下调用fork()函数,仅会将发起调用的线程复制到子进程中。(子进程中该线程的ID与父进程中发起fork()调用的线程ID是一样的,因此,线程ID相同的情况有时我们需要做特殊的处理。)也就是说不能同时创建出于父进程一样多线程的子进程。其他线程均在子进程中立即停止并消失,并且不会为这些线程调用清理函数以及针对线程局部存储变量的析构函数。这将导致下列一些问题:




