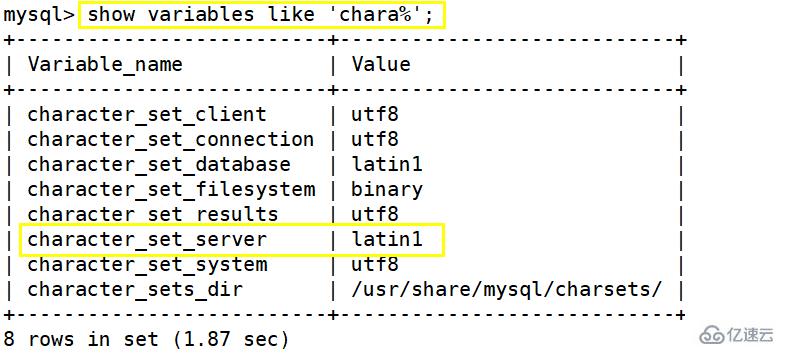
(1)查看集群状态,发现2个osd状态下为
<代码> root@node140/# ceph - s 集群: id: 58 a12719-a5ed-4f95-b312-6efd6e34e558 健康:HEALTH_ERR noout国旗(s) 2 osd下来 1擦洗错误 可能的数据损失:1 pg不一致 退化数据冗余:1633/10191物体退化(16.024%)、84后卫退化,122后卫矮小 服务: 星期一:2守护进程、群体node140 node142(年龄3 d) 经理:管理(活跃,因为3 d),备用:node140 osd: 18 osd: 16 (3 d)以来,18(因为5 d) 旗帜noout 数据: 池,池:384动力分配 对象:3.40 k对象,9.8直布罗陀海峡 用法:使用43镶条,8.7 TiB/8.7 TiB的效果 后卫:1633/10191对象退化(16.024%) 261活跃+清洁 84活跃+身高+退化 38活跃+尺寸过小 1积极+清洁+不一致
(2)查看osd状态
<代码> [root@node140/] # ceph osd树 ID类重量类型名称状态调整PRI-AFF 1根9.80804默认 2 3.26935主机node140 0 osd 0.54489硬盘。0 1.00000 1.00000 1硬盘0.54489 osd。1 1.00000 1.00000 2硬盘0.54489 osd。2到1.00000 - 1.00000 3 osd 0.54489硬盘。3到1.00000 - 1.00000 4硬盘0.54489 osd。4到1.00000 - 1.00000 5个硬盘0.54489 osd。5到1.00000 - 1.00000 3 3.26935主机node141 12个0.54489 osd硬盘。12 1.00000 1.00000 13 osd 0.54489硬盘。13 1.00000 1.00000 14 osd 0.54489硬盘。14个1.00000 1.00000 15 osd 0.54489硬盘。15 1.00000 1.00000 16个0.54489 osd硬盘。16个1.00000 1.00000 17 osd 0.54489硬盘。17日上涨1.00000 1.00000 4 3.26935主机node142 6 osd 0.54489硬盘。6到1.00000 - 1.00000 7 osd 0.54489硬盘。7到1.00000 - 1.00000 8 osd 0.54489硬盘。8到1.00000 - 1.00000 9 osd 0.54489硬盘。9到1.00000 - 1.00000 10硬盘0.54489 osd。10到1.00000 - 1.00000 11 osd 0.54489硬盘。11 1.00000 1.00000
(3) osd 7 osd 8状态查看,已经失败了,重启也无法启动
<代码> [root@node140/] # ceph-osd@8.service systemctl状态
●ceph-osd@8。服务——Ceph osd.8对象存储的守护进程
加载:加载(/usr/lib/systemd/系统/ceph-osd@.service;启用;厂商预设:禁用)
活动:失败(结果:start-limit)自星期五以来2019-08-30 17:36:50中科;1分钟20年代以前
过程:433642 ExecStartPre=/usr/lib/ceph/ceph-osd-prestart。sh——集群${集群}- id %我(状态退出代码=,=1/失败)
8月30日17:36:50 node140 systemd[1]:未能Ceph对象存储守护进程osd.8开始。
8月30日17:36:50 node140 systemd [1]: ceph-osd@8单位。服务失败的国家。
8月30日17:36:50 node140 systemd [1]: ceph-osd@8。服务失败。
8月30日17:36:50 node140 systemd [1]: ceph-osd@8。服务拖延时间,安排重启。
8月30日17:36:50 node140 systemd[1]:停止Ceph osd.8对象存储的守护进程。
8月30日17:36:50 node140 systemd[1]:开始为ceph-osd@8.service过快请求重复
8月30日17:36:50 node140 systemd[1]:未能Ceph对象存储守护进程osd.8开始。
8月30日17:36:50 node140 systemd [1]: ceph-osd@8单位。服务失败的国家。
8月30日17:36:50 node140 systemd [1]: ceph-osd@8。服务失败了。
(4) osd硬盘故障,状态变化
osd硬盘故障,状态变为下来。在经过国防部osd降下来间隔设定的时间间隔后,ceph将其标记为,并开始进行数据迁移恢复。为了降低影响可以先关闭,待硬盘更换完成后再开启
[root@node140/] #猫/etc/ceph/ceph.参看
(全球)
我的osd降下来间隔=900
(5)停止数据均衡
[root@node140/] #我在noout nobackfill norecover noscrub nodeep-scrub; ceph osd设置$ i;做了
(6)定位我故障盘
[root@node140/] # ceph osd树| grep - i
7硬盘0.54489 osd。7 0 1.00000
8 osd 0.54489硬盘。8 0 1.00000
(7)卸载故障的节点
[root@node142 ~] # umount/var/lib/ceph/osd/ceph-7来
[root@node142 ~] # umount/var/lib/ceph/osd/ceph-8来
(8)从粉碎地图中移除osd
[root@node142 ~] # ceph osd粉碎删除osd。7
删除项id 7 osd的名字”。7从粉碎地图
[root@node142 ~] # ceph osd粉碎删除osd。8
删除项id 8 osd的名字”。8从粉碎地图
(9)删除故障osd的密钥
root@node142 ~ # ceph auth del osd。更新7
[root@node142 ~] # ceph auth del osd.8
(10)删除故障osd
<代码> [root@node142 ~] # ceph osd rm 7 删除osd.7 (root@node142 ~) # ceph osd rm 8 删除osd.8 (root@node142 ~) # ceph osd树 ID类重量类型名称状态调整PRI-AFF 1根8.71826默认 2 3.26935主机node140 0 osd 0.54489硬盘。0 1.00000 1.00000 1硬盘0.54489 osd。1 1.00000 1.00000 2硬盘0.54489 osd。2到1.00000 - 1.00000 3 osd 0.54489硬盘。3到1.00000 - 1.00000 4硬盘0.54489 osd。4到1.00000 - 1.00000 5个硬盘0.54489 osd。5到1.00000 - 1.00000 3 3.26935主机node141 12个0.54489 osd硬盘。12 1.00000 1.00000 13 osd 0.54489硬盘。13 1.00000 1.00000 null null null null null null null null null null null null(6)ceph集群osd下来故障处理