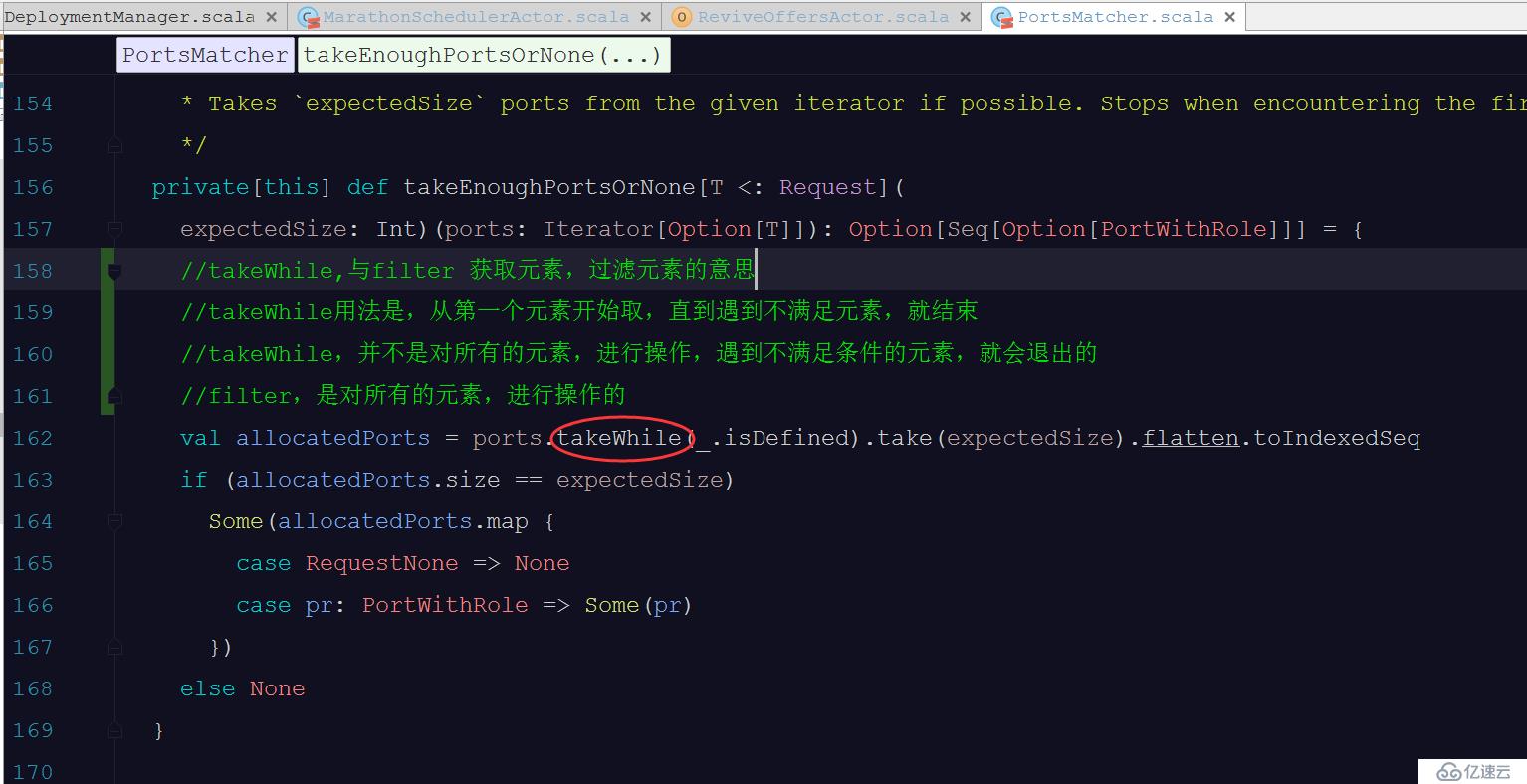
每天学一点Scala之花,takeRight, takeWhile与过滤器 比较简单,直接上例子 object takeWhileTest { ,,def 主要(args:数组[String]):, Unit =, { ,,,,,val names =,列表(“火花”,“hadoop”、“卡夫卡”、“蜂巢”,“便”,“零”,“xyz”、“马拉松”) ,,,,,//需求:将名字容器中,获?过滤出元素长度为4的元素, ,,,,,,,//takeWhile从第一个元素开始判断,满足条件,就留下,直到遇到第一个不满足的条件的元素,就结束循环 ,,,,,//可见,takeWhile 有可能并不是对所有的元素进行操作的 ,,,,,names.takeWhile(祝辞_.length 4,) .foreach {x =祝辞,打印(x +, ", ")} ,,,,,println (“\ n - - - - - - - - - - - - - - - - - -”) ,,,,,//从左边开始获取2个元素, ,,,,,names.take (2) .foreach {x =祝辞,打印(x +, ", ")} ,,,,,println (“\ n - - - - - - - - - - - - - - - - - -”) ,,,,,//从右边开始获取4个元素, ,,,,,names.takeRight (4) .foreach {x =祝辞,打印(x +, ", ")} ,,,,,println (“\ n - - - - - - - - - - - - - - - - - -”) ,,,,,//过滤器,,同样,满足条件,就留下。是对所有的元素,进行操作的 ,,,,,names.filter(祝辞_.length 4) .foreach {x =祝辞,打印(x +, ", ")}//将“xyz”元素,过滤掉了 ,,} } 结果: spark hadoop kafka ------------------ spark hadoop ------------------ mesos zero xyz marathon ------------------ spark hadoop kafka mesos 马拉松 同样,马拉松源码中,也有体现,如下: 每天学一点Scala之花,takeRight, takeWhile与过滤器 上一篇 下一篇 赞