,, 这段时间在看周志华大佬的《机器学习》,在看书的过程中,有时候会搜搜其他人写的文章,对比来讲,周教授讲的内容还是比较深刻的,但是前几天看到支持向量机这一章的时候,感觉甚是晦涩啊,第一感觉就是比较抽象,特别是对于像本人这种智商不怎么高的,涉及到高维向量之后,对模型的理解就比较懵了,特别是对于那个几何距离(或者说是最大间隔),一直是模棱两可,似懂非懂的感觉,本人也看了其他人写的SVM的文章,好多都没用讲清楚那个最大间隔模型 d=1/| |女| |为什么分子是1而不是f (x) | |。苦思冥想之后,给了一个适合自己理解的解释。
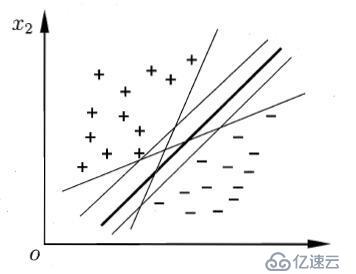
,, 现有n维数据集Dx={x1, x2, x3,……,,…, xn},其中样本xi的类别易∈Y={+ 1,1}即数据集为D,且D={d1, d2,…,di,…,dm }={(x1, y1), (x2, y2), (x3, y3)……(xj, yj) (xm, ym)}。其样本分布如下图所示: